차등 프라이버시 ε(엡실론): 평균 연봉 발표로 이해하는 보호 원리
차등 프라이버시 ε은 한 사람이 데이터에 있든 없든 결과가 크게 달라 보이지 않게 묶는 약속입니다. 평균 연봉 예시로 공격자가 무엇을 못 하게 되는지 쉽게 풉니다.
정현진(Hyunjin Jeong) · 2026-05-14 · 5분 분량

어떤 회사가 직원 1,000명의 평균 연봉을 발표했습니다.
‘4,650만 원.’
당신은 옆집 김 부장이 그 회사 직원이라는 사실을 압니다. 다만 그가 이번 평균 계산에 들어간 1,000명 중 한 명인지, 빠진 사람인지는 모릅니다.
이때 공격자가 궁금한 것은 딱 하나입니다.
‘저 평균값을 보면 김 부장이 포함됐는지 알 수 있을까?’
차등 프라이버시의 ε(엡실론)은 바로 이 질문을 막는 숫자입니다. 평균을 못 내게 하는 기술이 아닙니다. 평균은 공개하되, 그 평균만 보고 특정 사람이 들어 있었는지 알아내기 어렵게 만드는 약속입니다.
한 줄 요약: ε은 한 사람이 데이터에 있든 없든 공격자의 판단이 크게 달라지지 않게 묶는 숫자입니다. ε=0.1이면 공격자가 거의 새 정보를 얻지 못하고, ε=1이면 판단이 어느 정도 흔들릴 수 있지만 여전히 상한이 있습니다. 이름만 지우는 비식별화와 달리, 차등 프라이버시는 외부 데이터를 가진 공격자까지 가정하고 보호 강도를 숫자로 말합니다.
공격자가 보는 두 장면
공격자의 머릿속에는 두 장면이 있습니다.
- 장면 A: 김 부장이 평균 계산에 들어갔다.
- 장면 B: 김 부장은 평균 계산에서 빠졌다.
두 장면은 김 부장 한 사람만 다릅니다. 차등 프라이버시에서는 이렇게 한 사람만 다른 두 데이터셋을 이웃 데이터셋이라고 부릅니다.
공격자는 발표된 4,650만 원을 보고 묻습니다.
‘이 숫자는 장면 A에서 더 그럴듯한가, 장면 B에서 더 그럴듯한가?’
차등 프라이버시는 이 둘의 차이를 작게 묶습니다. 김 부장이 들어갔든 빠졌든, 발표값만 보고 공격자의 확신이 확 뛰면 안 됩니다. 이것은 데이터에 참여했다는 이유만으로 개인이 추가 피해를 크게 입지 않게 하려는 보장입니다.1
NIST SP 800-226도 같은 관점에서 차등 프라이버시를 설명합니다. 특정 개인의 데이터가 있는 세계와 없는 세계에서 같은 결과가 나올 가능성을 비교하는 틀입니다.2
ε은 개인정보 노출 다이얼입니다
ε은 개인정보 노출 다이얼이라고 보면 됩니다.
다이얼을 낮추면 보호가 강해집니다. 대신 통계에는 더 큰 노이즈가 섞입니다. 다이얼을 높이면 통계는 더 또렷해지지만, 개인의 흔적도 더 잘 보입니다.
이 다이얼이 기존 비식별화와 다른 점은 세 가지입니다.
첫째, 숫자로 말합니다.
‘충분히 익명화했습니다’가 아니라 ‘ε=1입니다’라고 말합니다. 보호 강도가 숫자로 남습니다.
둘째, 수학적으로 검증할 수 있습니다.
NIST는 차등 프라이버시를 데이터가 포함될 때의 프라이버시 손실을 정량화하는 수학적 프레임워크로 설명합니다.2
셋째, 정확도와 맞교환됩니다.
ε을 낮추면 보호는 강해지지만 결과는 더 흐려집니다. ε을 높이면 결과는 더 정확해지지만 보호는 약해집니다. ε이 작을수록 프라이버시는 좋아지고 응답은 덜 정확해집니다.1
여기서 중요한 점이 하나 있습니다. ε은 평균 손실이 아닙니다. 최악의 경우에도 여기까지만이라는 천장입니다. NIST도 개인이 실제로 겪는 손실은 ε보다 클 수 없고, 실제로는 더 작을 수도 있다고 설명합니다.2
김 부장 입장에서는 이런 뜻입니다.
‘공격자가 발표값을 보더라도, 내 포함 여부에 대한 확신이 올라갈 수 있는 폭을 미리 막아 두겠다.’
ε=0.1, 1, 10은 얼마나 다를까
차등 프라이버시 정의에서 ε은 공격자의 판단이 최대 몇 배까지 흔들릴 수 있는지를 정합니다. 수식을 몰라도 표만 보면 감이 잡힙니다.
| ε 값 | 공격자 판단이 흔들릴 수 있는 폭 | 느낌 |
|---|---|---|
| 0.1 | 약 1.1배 | 거의 못 흔듦 |
| 1 | 약 2.7배 | 흔들리지만 상한이 있음 |
| 10 | 약 22,000배 | 사실상 보호 의미가 매우 약함 |
ε=0.1이면 공격자는 발표값을 봐도 거의 새로 알 게 없습니다. ‘김 부장이 있었다’와 ‘없었다’의 그럴듯함이 거의 비슷하게 남습니다.
ε=1이면 차이가 최대 약 2.7배까지 벌어질 수 있습니다. 판단이 움직일 수는 있지만, 마음대로 폭주하지는 못합니다.
ε=10이면 이야기가 달라집니다. 2만 배 넘게 벌어질 수 있으니, 숫자만 차등 프라이버시일 뿐 실질 보호는 매우 약합니다.
조금 더 현실적으로 보겠습니다. 공격자가 발표 전에는 ‘김 부장이 포함됐을 가능성’을 50%로 봤다고 합시다.
ε=0.1이면 결과를 본 뒤에도 그 확신은 약 52.5% 정도까지밖에 못 올라갑니다. 거의 제자리입니다.
ε=1이면 최대 약 73%까지 올라갈 수 있습니다. 꽤 움직이지만, 그래도 단정은 아닙니다.
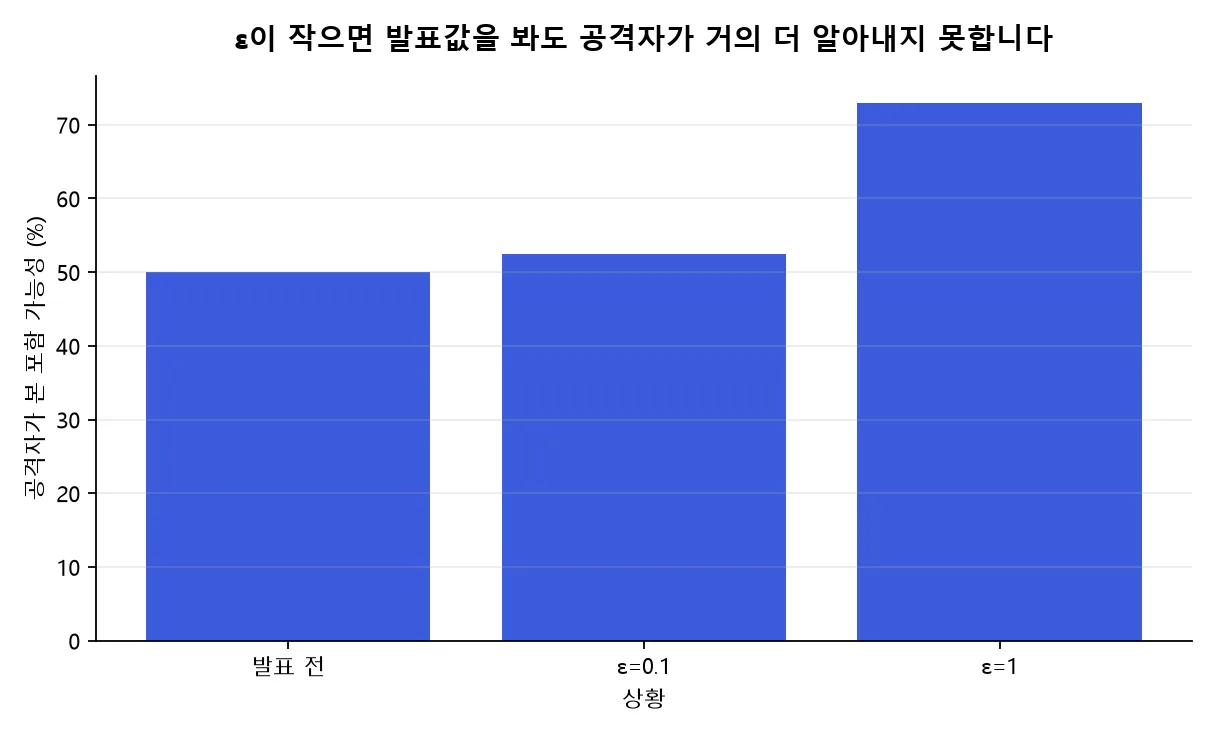
발표 전 50%로 보던 포함 가능성의 최대 상승폭. ε=0.1은 거의 제자리, ε=1은 73%.
이 계산은 차등 프라이버시의 베이즈 해석에서 나오는 결과입니다. 공격자가 결과를 보고 믿음을 갱신하더라도 그 폭이 ε으로 제한된다는 점이 수학적으로 증명돼 있습니다.3
공격자가 똑똑해도 상한은 남습니다
차등 프라이버시가 강한 이유는 공격자를 순진하게 보지 않기 때문입니다.
공격자가 외부 데이터를 많이 갖고 있어도 됩니다. 더 좋은 알고리즘을 써도 됩니다. 아직 나오지 않은 미래의 추론 도구를 쓴다고 해도, 차등 프라이버시가 요구하는 상한은 그대로입니다.
NIST는 차등 프라이버시가 보조 데이터를 쓰는 공격까지 포함해 잠재적 공격 전반에 대한 보호를 제공한다고 설명합니다.2
통계적 검정 관점에서도 결론은 같습니다.4 ε-차등 프라이버시가 성립하면, 멤버십을 맞히려는 검정의 힘도 제한됩니다. 공격자가 통계학의 정공법을 들고 와도, 맞힐 수 있는 폭에 천장이 생깁니다.
물론 어느 ε이 적정한지는 별도 문제입니다. NIST는 모든 상황에 통하는 단일 ε 값을 제시하지 않습니다. 데이터가 얼마나 민감한지, 통계가 얼마나 정확해야 하는지, 어떤 맥락에서 쓰이는지에 따라 달라지기 때문입니다.2
이름만 지우는 것과 무엇이 다른가
기존 비식별화는 대개 이렇게 말합니다.
‘이름을 지웠습니다.’
‘주민번호를 뺐습니다.’
‘같은 속성을 가진 사람이 k명 이상 남도록 묶었습니다.’
필요한 조치들입니다. 하지만 이것만으로는 부족할 때가 많습니다. 공격자가 어떤 외부 데이터를 들고 올지 알 수 없기 때문입니다.
Netflix 데이터 재식별 사례가 대표적입니다. 공개된 Netflix 기록에서 가입자 한 명당 평점 몇 개만 알아도 개인을 식별할 수 있다는 것이 연구로 밝혀졌습니다. 일부 정보가 틀려도 공격은 작동했습니다.5
NIST가 소개하는 더 오래된 사례도 있습니다. 1997년 연구자들은 성별, 우편번호, 생년월일 조합만으로 비식별 의료기록 속 매사추세츠 주지사 William Weld를 재식별했습니다. 같은 연구에서 미국 인구의 87%가 이 세 요소만으로 유일하게 식별된다는 사실도 확인됐습니다.2
이름을 지워도 조각이 충분하면 사람은 다시 나타납니다.
차등 프라이버시가 다른 지점은 여기입니다. ε은 ‘외부 데이터가 없으면 안전하다’가 아니라, 외부 데이터를 가진 공격자까지 가정하고 두 장면의 차이를 숫자로 묶습니다.
정성적 비식별화가 담당자의 판단에 기대는 보호라면, 차등 프라이버시는 보호 강도를 보고서와 감사 문서에 적을 수 있는 숫자로 바꿉니다. 평균 연봉 발표가 김 부장을 지킬 수 있는 근거는 ‘이름을 지웠다’가 아니라, 발표값이 그의 포함 여부를 얼마나 못 드러내게 만들었는지를 ε로 제한했다는 데 있습니다.
마지막으로 한 가지를 덧붙이면, ε 하나만 외워서는 부족합니다. 같은 ε이라도 보호 단위, δ, 예산 회계 방식에 따라 실제 의미가 달라집니다. ε은 출발점입니다. 진짜 검토는 그 숫자가 어떤 조건 위에 올라가 있는지까지 봐야 끝납니다.
참고 문헌
Footnotes
-
Dwork, C., Roth, A. — The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩ ↩2
-
Near, J., Darais, D., et al. — Guidelines for Evaluating Differential Privacy Guarantees (NIST SP 800-226), NIST, 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Kasiviswanathan, S. P., Smith, A. — On the 'Semantics' of Differential Privacy: A Bayesian Formulation, 2014 (arXiv 2008). https://arxiv.org/abs/0803.3946 ↩
-
Wasserman, L., Zhou, S. — A Statistical Framework for Differential Privacy, JASA, 2010 (arXiv 2008). https://arxiv.org/abs/0811.2501 ↩
-
Narayanan, A., Shmatikov, V. — How To Break Anonymity of the Netflix Prize Dataset, 2006. https://arxiv.org/abs/cs/0610105 ↩