차등 프라이버시 ε=1이 늘 같은 보호는 아닙니다: 이웃 모델과 δ
같은 ε=1이라도 한 사람을 추가·제거로 볼지 교체로 볼지, δ를 얼마로 둘지에 따라 실제 보호가 달라집니다. 이웃 모델과 δ를 사례 중심으로 풉니다.
정현진(Hyunjin Jeong) · 2026-05-20 · 5분 분량
두 회사가 같은 날 이렇게 발표했다고 해 봅시다.
‘우리는 고객 데이터를 ε=1로 보호합니다.’
숫자가 같으니 보호도 같아 보입니다. 그런데 차등 프라이버시에서는 여기서 바로 믿으면 안 됩니다. ε=1 뒤에 빠진 조건이 있기 때문입니다.
첫째, 한 사람이 바뀐다는 말을 명단에 들어오거나 빠지는 것으로 볼지, 한 사람을 다른 사람으로 바꾸는 것으로 볼지 정해야 합니다.
둘째, ε 보장이 아주 드물게 깨질 수 있는 확률인 δ(델타)를 밝혀야 합니다.
이 둘을 숨기면 같은 ε=1이 전혀 다른 보호를 뜻할 수 있습니다. 숫자는 같지만 계약서 조항이 다른 셈입니다.
한 줄 요약: ε은 혼자 비교하면 안 됩니다. 한 사람을 추가·제거하는 모델과 교체하는 모델은 같은 쿼리에서도 필요한 노이즈가 달라질 수 있습니다. 또 δ가 크면 ‘아주 드문 예외’라는 이름으로 큰 정보 노출이 숨어 들어갈 수 있습니다. 그래서 ε은 반드시 이웃 모델, δ, 데이터 인원수와 함께 적어야 합니다.
ε=1만으로는 비교가 안 됩니다
NIST SP 800-226은 차등 프라이버시 보장이 ε 같은 숫자 하나로 정해지지 않는다고 설명합니다. 보호 단위와 이웃 데이터셋 정의가 함께 있어야 합니다.1
ε은 보호의 세기입니다. 하지만 무엇을 한 단위로 바꾸는지는 말해 주지 않습니다.
‘시속 80’이라고만 적힌 표지판을 떠올려 봅시다. 킬로미터인지 마일인지 빠져 있으면 숫자를 봐도 제대로 비교할 수 없습니다.
ε도 같습니다. ε=1이라는 라벨만 보고 두 시스템을 같은 줄에 세우면 위험합니다. 그 라벨 뒤에 숨어 있는 첫 번째 단서가 이웃 모델입니다.
한 사람을 빼는가, 한 사람을 바꾸는가
차등 프라이버시에서 이웃 데이터셋은 한 사람만 다른 두 데이터셋입니다. 그런데 ‘한 사람만 다르다’를 보는 방식이 둘입니다.
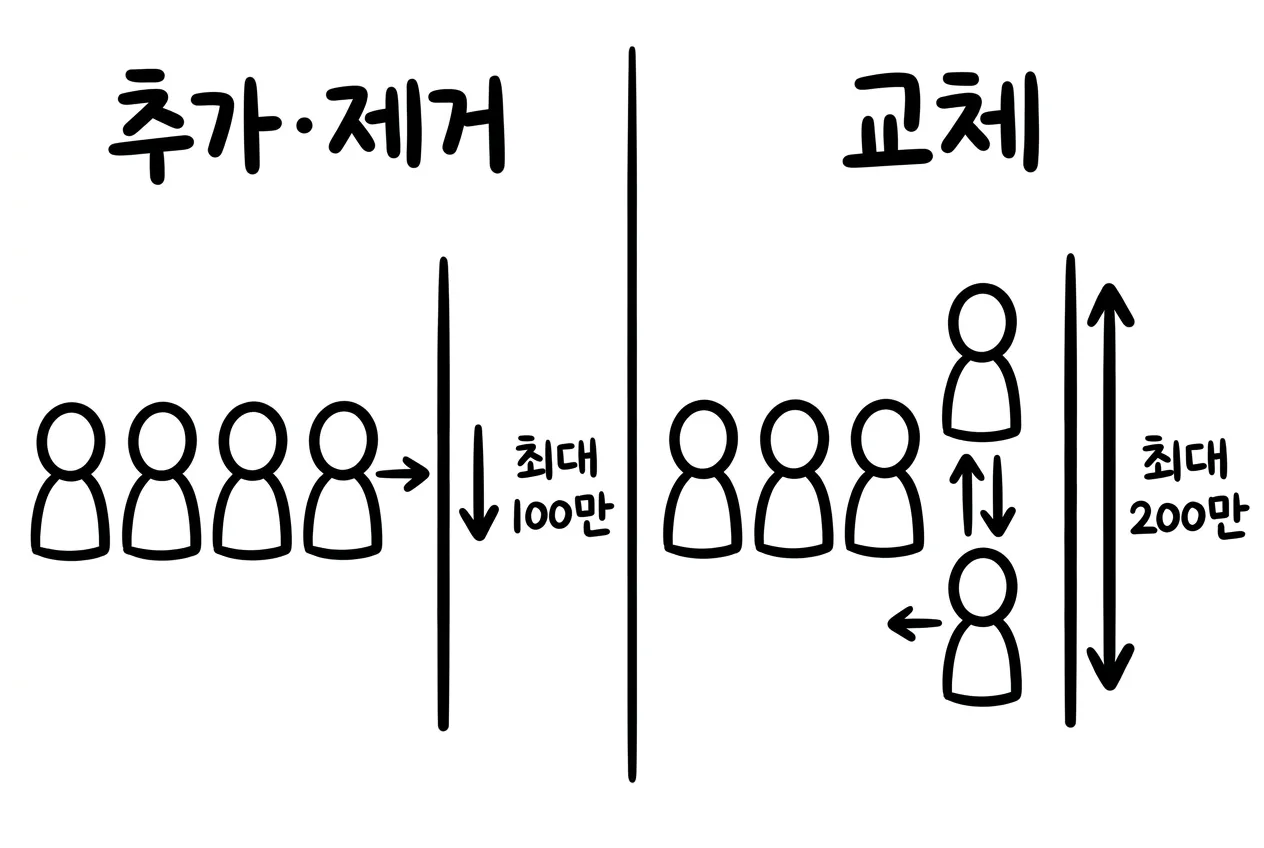
- 추가·제거 모델(add-remove / unbounded): 한 사람이 명단에 들어오거나 빠집니다.
- 교체 모델(swap / bounded): 명단 인원수는 그대로 두고, 한 사람을 다른 사람으로 바꿉니다.
어느 쪽이 절대적으로 맞다는 뜻은 아닙니다. 문제에 따라 선택이 달라집니다. 중요한 것은 두 모델이 같은 노이즈를 요구하지 않을 수 있다는 점입니다.
기부금 총액 예시로 보겠습니다.
직원 1,000명이 기부를 했고, 한 사람이 낼 수 있는 최대 금액은 100만 원입니다. 우리가 공개하려는 값은 전체 기부금 합계입니다.
추가·제거 모델에서는 한 사람이 빠지면 합계가 최대 100만 원 변합니다. 그 사람이 낸 돈만큼만 빠지기 때문입니다.
교체 모델에서는 더 크게 흔들릴 수 있습니다. 0원을 낸 사람이 100만 원을 낸 사람으로 바뀌거나, 반대로 100만 원을 낸 사람이 0원을 낸 사람으로 바뀔 수 있습니다. 두 끝을 오가는 폭은 200만 원입니다.
같은 기부금 합계인데, 교체 모델에서는 최대 변화 폭이 2배입니다.
| 항목 | 추가·제거 모델 | 교체 모델 |
|---|---|---|
| 한 사람 변화로 합계가 흔들릴 수 있는 최대 폭 | 100만 원 | 200만 원 |
| ε=1을 지키는 데 필요한 노이즈 폭 | 100만 원 기준 | 200만 원 기준 |
| 추가·제거용 노이즈를 그대로 쓰면 | ε=1 | 실질적으로 ε=2 수준 |
여기서 실무 함정이 생깁니다. 교체 모델을 쓰면서 추가·제거 모델용 노이즈만 넣으면 보호가 약해집니다. ‘ε=1’이라고 적었지만 실제로는 더 큰 ε에 가까운 보호가 됩니다.
히스토그램에서도 같은 일이 벌어집니다. 한 사람을 다른 칸으로 옮기면 한 칸은 1 줄고, 다른 칸은 1 늘어납니다. 이런 이유로 교체 모델 상황에서는 L1 민감도가 2가 될 수 있습니다.2
용어 정리
- 이웃 데이터셋: 한 사람의 데이터만 다른 두 데이터셋입니다.
- 민감도: 한 사람이 바뀔 때 결과가 최대 얼마나 움직이는지의 상한입니다.
- 추가·제거 모델: 한 사람이 들어오거나 빠지는 기준입니다.
- 교체 모델: 한 사람을 다른 사람으로 바꾸는 기준입니다.
δ는 ‘아주 드문 예외’입니다
ε 옆에 붙는 δ는 보장이 아주 드물게 깨질 수 있는 확률입니다.
ε=1, δ=0.0000001이라면 이런 뜻입니다.
‘대부분의 경우에는 ε=1 한도를 지키지만, 1,000만 번 중 한 번꼴의 예외는 허용한다.’
δ=0이면 이런 예외가 없는 순수 ε-DP입니다.
NIST는 δ를 더 조심스럽게 다룹니다. δ는 드문 사건에 대해 프라이버시를 전혀 보장하지 않게 허용할 수 있는 파라미터이며, 그 작은 확률 안에서는 프라이버시가 완전히 무너질 수도 있다고 설명합니다.1
그래서 δ는 작아야 합니다. ‘작아 보이는 숫자’면 안 됩니다. 데이터 크기와 비교해 충분히 작아야 합니다.
δ는 전체 인원의 역수보다 훨씬 작아야 합니다
데이터에 들어 있는 사람이 모두 n명이라고 해 봅시다. 이때 δ가 너무 크면 이상한 일이 생깁니다.
NIST의 예를 보겠습니다. 전체 인원 중 한 사람을 무작위로 골라 그 사람의 데이터를 노이즈 없이 그대로 공개하는 엉터리 메커니즘이 있다고 합시다. 그런데 δ가 전체 인원의 역수보다 크면, 이런 말도 정의상 통과할 수 있습니다.1
‘아주 드문 예외였으니 괜찮다.’
하지만 한 사람의 데이터가 통째로 공개됐는데 괜찮을 리가 없습니다. 그래서 δ는 전체 인원의 역수보다 훨씬 작아야 합니다. δ가 데이터 크기의 역수 수준이면 위험합니다.3
숫자로 보면 더 쉽습니다.
| 인원 | 전체 인원의 역수 | 보수적 δ 예시 | δ=0.00001이라면 |
|---|---|---|---|
| 1,000,000 | 0.000001 | 0.000000000001 또는 약 0.00000007 | 전체 인원의 역수보다 큼. 정당화 없이는 위험 |
인원이 100만 명이면 전체 인원의 역수는 0.000001입니다. δ=0.00001은 그보다 큽니다. NIST는 0.00001을 넘는 δ는 의심스럽고, 사용하려면 신중한 정당화가 필요하다고 봅니다.1
작은 데이터에서는 더 조심해야 합니다. 환자 1,000명의 데이터에서 δ=0.001이면 전체 인원의 역수와 같습니다. ‘환자 1,000명 중 한 명이 통째로 드러나는 사건’을 예외로 밀어 넣을 수 있는 크기입니다.
가우시안에 δ가 필요한 이유
라플라스 메커니즘은 δ=0인 순수 ε-DP를 만족할 수 있습니다. 반면 가우시안 메커니즘은 보통 δ가 필요합니다. NIST도 순수 ε-DP가 필요하면 가우시안 메커니즘은 적절하지 않다고 설명합니다.1
이유는 노이즈 분포의 꼬리 모양입니다. 라플라스는 모든 구간에서 확률 비율 조건을 맞출 수 있지만, 가우시안은 아주 먼 꼬리에서 그 조건을 완벽히 맞추지 못합니다. 그 맞추지 못하는 작은 부분을 δ로 떼어 둡니다.
따라서 δ는 장식용 숫자가 아닙니다. 어떤 메커니즘을 쓰는지, 어떤 데이터 크기인지, 얼마나 드문 예외를 허용할지에 직접 연결됩니다.
결론: ε은 반드시 세트로 적어야 합니다
처음의 발표로 돌아가 봅시다.
‘ε=1로 보호합니다.’
이 말만으로는 부족합니다. 최소한 아래 정보가 함께 있어야 합니다.
- 이웃 모델: 추가·제거인가, 교체인가
- δ: 예외 확률은 얼마인가
- n: 데이터에 몇 명이 있는가
- 보호 단위: 한 줄인가, 한 사람인가
실무에서는 이렇게 적어야 비교가 됩니다.
ε=1, 이웃 모델: 교체, δ=0.0000001, 인원: 100만 명
이 정도는 적어야 두 시스템의 ε을 같은 자 위에 올릴 수 있습니다. 이웃 모델이 다르면 필요한 노이즈가 달라지고, δ가 다르면 예외 확률이 달라집니다.
같은 ε이라도 조건이 다르면 다른 보장입니다. ε은 천장 높이입니다. 이웃 모델은 그 천장을 어느 방에 걸었는지를 말하고, δ는 천장에 뚫어 둔 아주 작은 비상구입니다. 숫자만 보고 안심하면 안 됩니다.
참고 문헌
Footnotes
-
Near, J., Darais, D., et al. — Guidelines for Evaluating Differential Privacy Guarantees (NIST SP 800-226), NIST, 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2 ↩3 ↩4 ↩5
-
Dwork, C., McSherry, F., Nissim, K., Smith, A. — Calibrating Noise to Sensitivity in Private Data Analysis, TCC, 2006. https://people.csail.mit.edu/asmith/PS/sensitivity-tcc-final.pdf ↩
-
Dwork, C., Roth, A. — The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩