차등 프라이버시 ε 예산: 쿼리를 반복하면 보호가 줄어드는 이유
차등 프라이버시 ε은 같은 데이터에 쿼리를 거듭할수록 합산되는 프라이버시 예산입니다. 기본 합성, 고급 합성, RDP 회계를 장부 비유와 실제 운영 사례로 풉니다.
정현진(Hyunjin Jeong) · 2026-05-25 · 4분 분량

분석 팀이 같은 환자 데이터셋에 ε=0.1짜리 쿼리를 던졌습니다. 결과를 받고 나서, 곧바로 같은 데이터에 또 ε=0.1짜리 쿼리를 던집니다.
많은 사람이 여기서 착각합니다.
‘각 쿼리가 ε=0.1이면 계속 안전한 것 아닌가?’
아닙니다. 두 번째 결과가 공개되는 순간, 첫 번째 결과의 보호도 함께 약해집니다. 공격자는 발표값을 하나씩 따로 보지 않습니다. 둘을 나란히 놓고 맞춰 봅니다.
차등 프라이버시에서 ε은 한 번 쓰고 잊어도 되는 숫자가 아닙니다. 같은 데이터 위에서 질문을 반복할수록 쌓이는 프라이버시 예산입니다. 통장에서 돈을 쓰면 잔고가 줄듯, 쿼리를 던질수록 남은 프라이버시 여유가 줄어듭니다.
한 줄 요약: 같은 데이터에 차등 프라이버시 쿼리를 반복하면 ε은 누적됩니다. 가장 단순한 회계에서는 ε=0.1짜리 쿼리 10개가 누적 ε=1.0이 됩니다. 고급 합성이나 RDP는 쿼리 수가 많을 때 더 알뜰한 장부를 제공하지만, 언제나 이득인 만능 할인권은 아닙니다. 실제 시스템은 단발 ε이 아니라 누적 ε을 보고해야 합니다.
쿼리를 반복하면 보호가 약해집니다
이유는 공격자가 결과를 함께 보기 때문입니다.
첫 번째 발표만 보면 공격자가 얻는 힌트가 작을 수 있습니다. 두 번째 발표도 따로 보면 작아 보일 수 있습니다. 하지만 둘을 같이 보면 이야기가 달라집니다.
예를 들어 병원이 아래 두 통계를 공개했다고 해 봅시다.
- 작년 당뇨 환자 수
- 작년 50대 당뇨 환자 수
각 통계는 노이즈가 섞여 있습니다. 그래도 공격자는 두 숫자를 함께 놓고 비교합니다. 하나의 표가 다른 표를 검산하는 힌트가 됩니다.
차등 프라이버시는 이런 반복 공개를 자동으로 합산합니다. 여러 메커니즘을 공개할수록 누적 손실이 함께 쌓이도록 설계된 것이 DP의 기본 원리입니다.1
여기서 자동이라는 말이 중요합니다. 담당자가 장부를 안 적어도 손실은 사라지지 않습니다. 공격자는 이미 여러 결과를 같이 보고 있습니다.
기본 합성: 가장 단순한 덧셈 장부
가장 쉬운 회계가 기본 합성입니다.
규칙은 간단합니다.
쿼리마다 쓴 ε을 그냥 더합니다.
표 10개를 만들고 각 표에 ε=0.1을 썼다면 누적 ε은 1.0입니다.
| 공개한 표 수 | 표 하나당 ε | 누적 ε |
|---|---|---|
| 1개 | 0.1 | 0.1 |
| 5개 | 0.1 | 0.5 |
| 10개 | 0.1 | 1.0 |
| 100개 | 0.1 | 10.0 |
기본 합성 정리에 따르면 ε뿐 아니라 δ도 함께 더해집니다.1 예외 확률도 반복하면 쌓입니다.
기본 합성의 장점은 분명합니다.
- 항상 성립합니다.
- 누구나 손으로 검산할 수 있습니다.
- 감사 문서에 쓰기 쉽습니다.
단점도 분명합니다. 예산이 빨리 마릅니다.
병원이 1년 프라이버시 예산을 ε=1로 잡았다고 해 봅시다. 쿼리 하나에 ε=0.1씩 쓰면 10번째 쿼리에서 예산이 끝납니다. 11번째 분석을 하려면 쿼리당 ε을 더 낮춰 노이즈를 키우거나, 별도 예산을 승인받거나, 다음 기간을 기다려야 합니다.
고급 합성: 쿼리가 많을 때 빛납니다
여기서 이런 질문이 나옵니다.
‘더 똑똑한 장부를 쓰면 예산을 아낄 수 있지 않나?’
맞습니다. 하지만 조건이 있습니다. 쿼리 수가 충분히 많아야 합니다.
고급 합성은 반복 횟수가 많을 때 누적 ε을 더 타이트하게 잡아 주는 정리입니다. 대신 아주 작은 추가 실패 확률을 허용합니다.1
그런데 쿼리 수가 적을 때는 오히려 손해가 날 수 있습니다. 예를 들어 쿼리 10개, 각 쿼리 ε=0.1, 추가 실패 확률 0.00001이라는 조건에서는 고급 합성으로 계산한 누적 ε이 약 1.62가 됩니다. 기본 합성의 1.0보다 큽니다.
반대로 쿼리 수가 100개, 1,000개로 늘어나면 고급 합성이 유리해집니다.
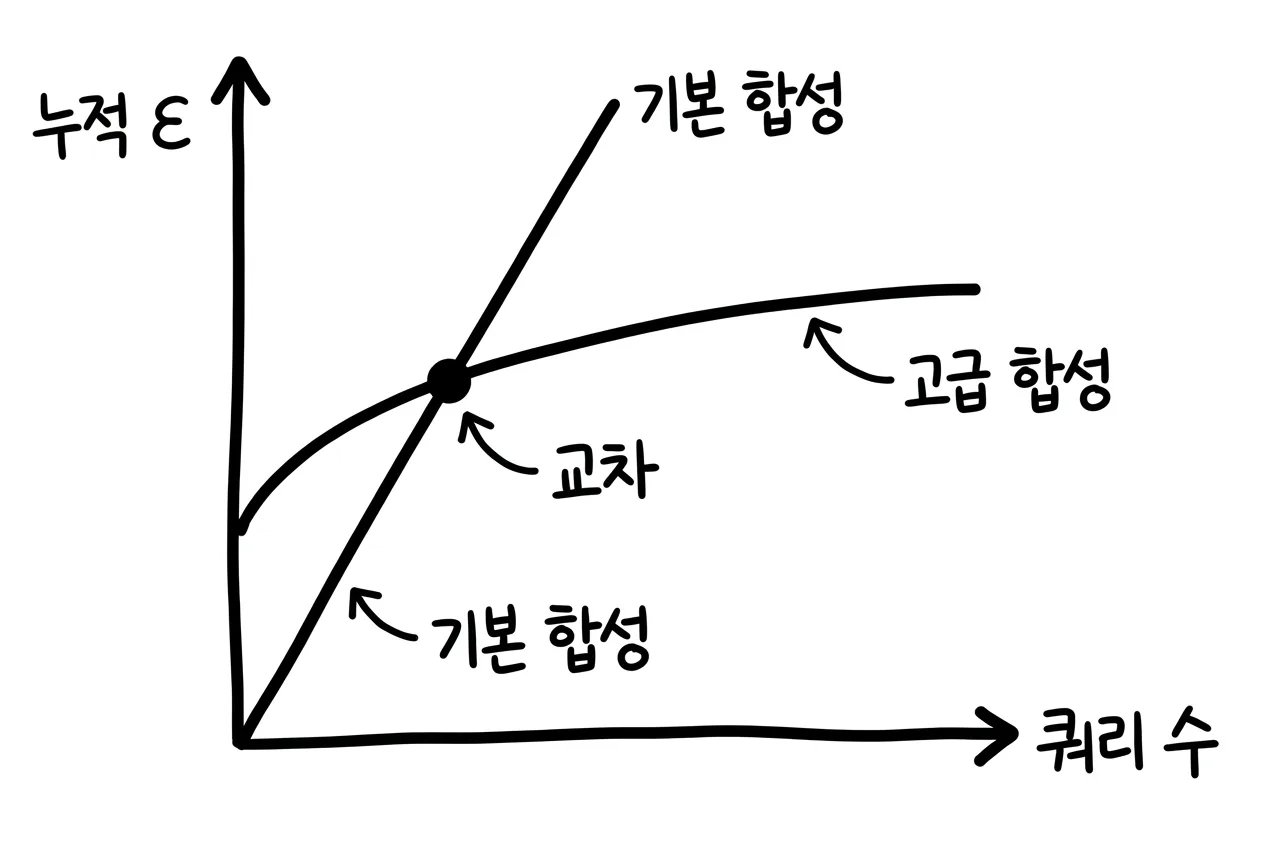
| 쿼리 수 | 기본 합성 누적 ε | 고급 합성 누적 ε | 더 유리한 장부 |
|---|---|---|---|
| 10 | 1.0 | 약 1.62 | 기본 합성 |
| 100 | 10 | 약 5.85 | 고급 합성 |
| 1,000 | 100 | 약 25.7 | 고급 합성 |
‘고급’이라는 이름만 보고 무조건 좋은 줄 알면 안 됩니다. 장부도 상황에 맞아야 합니다.
RDP: 반복 학습에 잘 맞는 다른 화폐 단위
가우시안 노이즈를 반복해서 쓰는 학습 시스템에서는 RDP(Rényi Differential Privacy)가 자주 쓰입니다. 손실을 다른 단위로 적립해 두었다가 마지막에 ε과 δ로 환산하는 방식입니다.2
거래할 때마다 바로 환산하지 않고, 반복 계산에 유리한 단위로 모아 두었다가 마지막에 바꾸는 셈입니다.
DP-SGD의 moments accountant, 즉 모멘트 회계가 대표 사례입니다. 프라이버시 손실 분포의 모양을 요약한 값을 추적하면, 강한 합성 정리보다 누적 ε을 훨씬 더 타이트하게 잡을 수 있습니다. 실제로 같은 학습 설정에서 강한 합성은 ε 약 9.34였지만, 모멘트 회계는 ε 약 1.26까지 낮췄습니다.3
회계 방식 하나로 보고되는 ε이 7배 넘게 달라진 셈입니다. 그래서 ‘우리 시스템은 ε=1입니다’라는 말에는 반드시 ‘어떤 회계로 합산했는가’가 따라와야 합니다.
실제 시스템은 누적 ε을 봅니다
운영 사례를 보면 단발 ε보다 누적 ε이 중요하다는 점이 더 분명합니다.
| 운영 주체 | 공개된 값 | 읽을 때 주의할 점 |
|---|---|---|
| Apple iOS·macOS | 데이터 1건당 ε=1 또는 2, 하루 최대 16 | 매일 예산이 새로 주어져 날짜만큼 누적될 수 있음 4 |
| Google RAPPOR | 1회 수집당 ε 약 1.10 | 같은 응답을 반복 수집하면 보장이 약해짐 5 |
| 미국 인구조사국 2020 | zCDP 총예산 ρ=2.63 | ρ는 ε과 다른 회계 단위이며 지리 계층에 배분됨 6 |
Apple 사례는 특히 직관적입니다. 한 분석에 따르면 macOS 10.12 구현에서 서버로 보내는 데이터 한 건당 손실은 ε=1 또는 2였습니다. 하지만 초기 네 기능을 합치면 하루 전체 손실은 최대 16까지 올라갈 수 있었습니다.4
게다가 예산은 매일 새로 주어졌습니다. 사용자가 옵트인한 지 30일이면 가능한 누적 손실은 최대 480입니다. ‘1건당 ε=1’과 ‘한 달 누적 최대 480’은 전혀 다른 말입니다.
Google RAPPOR도 1회 수집에서는 ε 약 1.10을 보장하지만, 같은 응답자에게 반복 수집하면 보장이 약해진다고 설명합니다.5
미국 인구조사국 2020 TopDown 알고리즘은 대규모 예산 배분 사례입니다. 최종 생산 설정은 zCDP 총예산 ρ=2.63이었습니다.6 여기서 ρ는 ε이 아닙니다. 나중에 선택한 δ에 따라 여러 ε 값으로 환산될 수 있는 다른 회계 단위입니다.
실무 규칙: ε은 장부와 함께 적습니다
NIST SP 800-226은 프라이버시 예산을 하나의 데이터셋을 처리하는 모든 분석에 걸친 누적 프라이버시 손실의 허용 상한으로 정의합니다.7
즉, 관리 대상은 한 번의 ε이 아니라 누적 손실입니다.
실무에서는 이렇게 적어야 합니다.
누적 ε=1.0, δ=0.00000001, 보호 단위: 사용자, 이웃 모델: 추가·제거, 회계: 기본 합성, 기간: 2026년 1분기
이 정도는 적어야 ‘우리는 ε로 보호합니다’가 검증 가능한 문장이 됩니다.
ε은 숫자 하나가 아니라 장부입니다. 장부가 맞아야 보호도 맞습니다.
참고 문헌
Footnotes
-
Dwork, C., Roth, A. — The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩ ↩2 ↩3
-
Mironov, I. — Rényi Differential Privacy, IEEE CSF, 2017. https://arxiv.org/abs/1702.07476 ↩
-
Abadi, M., et al. — Deep Learning with Differential Privacy, ACM CCS, 2016. https://arxiv.org/abs/1607.00133 ↩
-
Tang, J., Korolova, A., Bai, X., Wang, X., Wang, X. — Privacy Loss in Apple's Implementation of Differential Privacy on MacOS 10.12, 2017. https://arxiv.org/abs/1709.02753 ↩ ↩2
-
Erlingsson, Ú., Pihur, V., Korolova, A. — RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response, ACM CCS, 2014. https://arxiv.org/abs/1407.6981 ↩ ↩2
-
Abowd, J., et al. — The 2020 Census Disclosure Avoidance System TopDown Algorithm, 2022. https://arxiv.org/abs/2204.08986 ↩ ↩2
-
Near, J., Darais, D., et al. — Guidelines for Evaluating Differential Privacy Guarantees (NIST SP 800-226), NIST, 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩