연합학습 DP-SGD에서 그래디언트 클리핑은 민감도 계약입니다
연합학습 DP-SGD에서 클리핑 기준 C가 왜 노이즈 크기와 ε 보장의 전제가 되는지, 수식보다 직관과 실무 함정 중심으로 설명합니다.
정현진(Hyunjin Jeong) · 2026-06-03 · 6분 분량
연합학습에 차등 프라이버시를 붙이다 보면 이런 생각이 들기 쉽습니다.
‘노이즈가 너무 커서 학습이 안 되네. 클리핑 기준을 키우면 정보가 덜 잘리니까 좋아지겠지?’
반만 맞습니다.
기준을 키우면 잘리는 정보는 줄어듭니다. 하지만 동시에 더 큰 노이즈가 필요합니다. 한 사람이 모델을 크게 흔들 수 있게 허용했으니, 그 흔적을 가리려면 더 두꺼운 안개를 뿌려야 합니다.
그래서 그래디언트 클리핑은 정확도를 높이는 꼼수가 아닙니다. 한 클라이언트의 업데이트가 전체 모델을 최대 얼마까지 흔들 수 있는지 정하는 민감도 계약입니다.
한 줄 요약: DP-SGD에서 클리핑 기준 C는 ‘한 사람 또는 한 클라이언트가 결과를 최대 얼마까지 흔들 수 있는가’를 정합니다. C를 작게 잡으면 데이터 신호가 잘리고, C를 크게 잡으면 필요한 노이즈가 커집니다. 연합학습에서는 샘플 하나가 아니라 클라이언트 전체 업데이트를 보호 단위로 보기 때문에, 클리핑 위치와 회계 가정을 특히 조심해야 합니다.
클리핑이 필요한 이유
그래디언트는 모델이 어느 방향으로 얼마나 움직여야 하는지 알려 주는 신호입니다.
문제는 이 신호의 길이가 원래는 제한돼 있지 않다는 점입니다. 어떤 샘플 하나가 아주 큰 그래디언트를 만들면, 그 샘플은 모델을 크게 흔들 수 있습니다.
차등 프라이버시는 이런 상태를 싫어합니다.
‘한 사람이 빠져도 결과가 거의 같아야 한다’는 약속을 하려면, 먼저 한 사람이 결과를 얼마나 흔들 수 있는지 상한을 정해야 합니다. 그 상한이 민감도입니다.
DP-SGD 원 논문의 설계 이유도 같습니다. 그래디언트 크기에 미리 정해진 상한이 없으면 프라이버시 보장을 줄 수 없으므로, 각 그래디언트의 L2 길이를 클리핑합니다.1
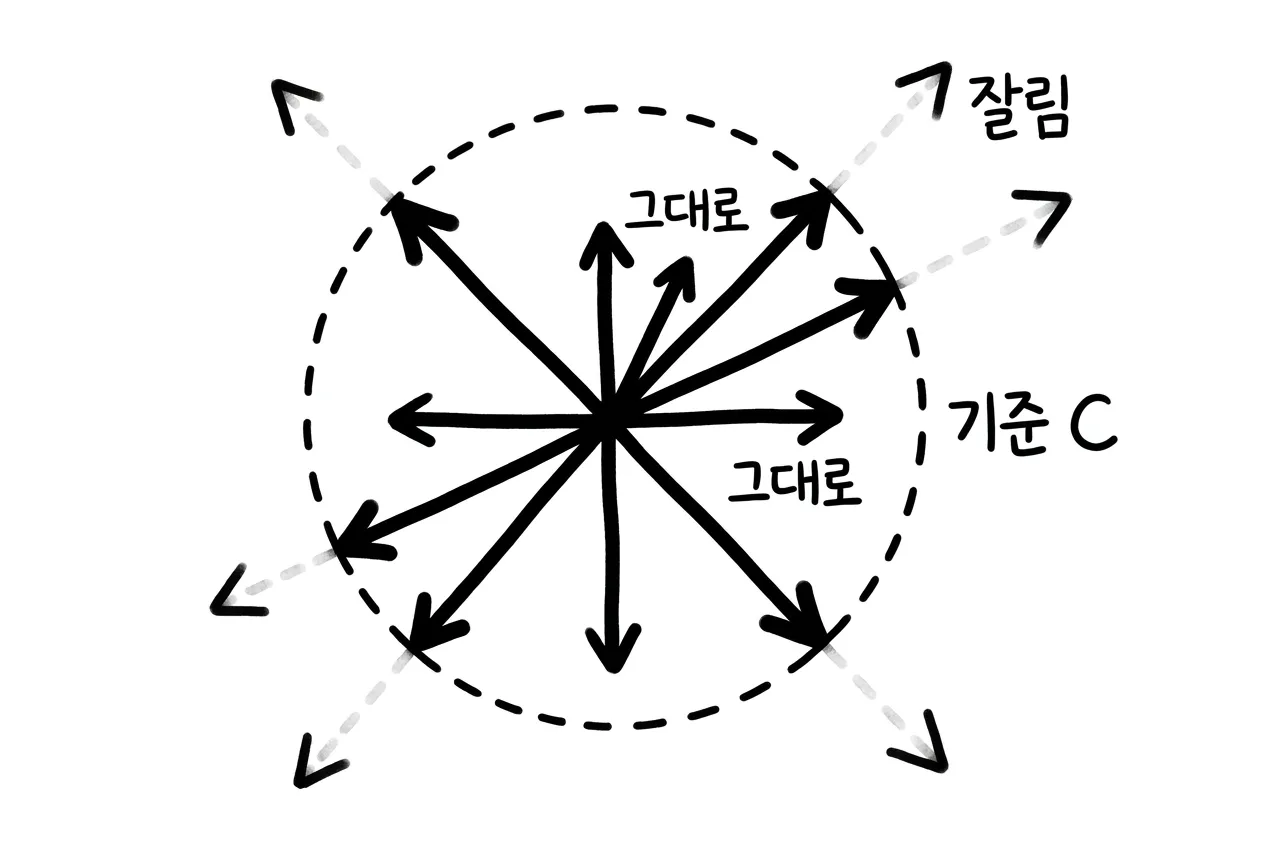
클리핑은 간단히 말해 이런 일입니다.
- 그래디언트 길이가 C보다 작으면 그대로 둡니다.
- C보다 크면 길이를 C로 줄입니다.
긴 막대를 자로 재고, C를 넘는 부분만 잘라내는 셈입니다.
그다음 잘린 그래디언트를 합치고 노이즈를 더합니다. 이때 노이즈 크기는 C에 비례합니다.1 C가 두 배가 되면, 같은 보호 강도를 유지하기 위해 필요한 노이즈도 대략 두 배가 됩니다.
그러니 C는 단순한 튜닝값이 아닙니다.
- 한 샘플 또는 한 클라이언트의 최대 영향력을 정합니다.
- 그 영향력을 가리기 위한 노이즈 크기의 기준이 됩니다.
연합학습에서는 ‘한 사람 전체’가 들어오고 빠집니다
중앙집중식 DP-SGD에서는 보통 샘플 하나를 보호 단위로 봅니다.
연합학습은 다릅니다. 스마트폰 하나, 병원 하나, 사용자 한 명이 로컬 데이터 여러 개를 들고 학습에 참여합니다. 그래서 보호 단위도 샘플 하나가 아니라 한 클라이언트의 데이터 전체가 됩니다.
연합학습 DP 설계에서는 한 사용자의 모든 샘플이 통째로 들어오거나 빠지는 것을 이웃 데이터셋으로 정의합니다.2
보호 단위가 바뀌면 클리핑 위치도 바뀝니다. 샘플별 그래디언트를 자르는 것이 아니라, 각 클라이언트가 로컬 학습으로 만든 업데이트 전체를 자릅니다.
예를 들어 스마트폰 1,000대가 학습에 참여했다고 합시다. 각 폰은 자기 안의 데이터를 가지고 모델 업데이트를 하나 만들어 보냅니다. 서버는 이 업데이트를 모아 전역 모델을 갱신합니다.
여기서 차등 프라이버시가 가리려는 것은 ‘어떤 폰 하나가 참여했는가’입니다. 따라서 폰 하나가 보낸 업데이트 전체의 길이를 제한해야 합니다.
수학적으로도, 클라이언트 업데이트의 길이를 상한 안에 묶으면 사용자 단위 민감도를 제한할 수 있습니다.2 표현은 복잡하지만 실무 메시지는 단순합니다.
클라이언트 업데이트에 건 클리핑 기준이 사용자 단위 민감도를 정합니다.
클라이언트 단위 DP는 전역 모델에 각 클라이언트의 업데이트를 가릴 만큼 노이즈를 더하는 방식입니다.3
C를 너무 작게 잡으면 신호가 잘립니다
클리핑 기준 C가 너무 작으면 많은 업데이트가 잘립니다.
예를 들어 클라이언트 업데이트 길이의 중앙값이 3이라고 해 봅시다. 그런데 C를 1로 잡으면 어떻게 될까요?
업데이트 절반 이상이 크게 잘립니다. 모델이 배워야 할 신호가 약해집니다. 보호는 강해질 수 있지만, 학습이 제대로 안 될 수 있습니다.
이것은 통계를 보호하려고 모든 목소리를 속삭임으로 줄이는 것과 비슷합니다. 개인정보는 덜 드러나지만, 회의 내용도 잘 안 들립니다.
C를 너무 크게 잡으면 노이즈가 커집니다
반대로 C를 너무 크게 잡으면 업데이트는 덜 잘립니다. 언뜻 좋아 보입니다.
하지만 대가가 있습니다. 한 클라이언트가 모델을 더 크게 흔들 수 있으니, 그 흔적을 가리기 위한 노이즈도 커집니다.
실제로 MNIST 실험 결과, 클리핑 기준을 고정하고 노이즈 배수만 키웠을 때 보호는 강해졌지만 정확도는 97%에서 90%로 떨어졌습니다.1
| 노이즈 배수 | 정확도 | 프라이버시 보장 |
|---|---|---|
| 2 | 97% | ε=8, δ=0.00001 |
| 4 | 95% | ε=2, δ=0.00001 |
| 8 | 90% | ε=0.5, δ=0.00001 |
방향은 분명합니다. 보호를 강하게 하려면 노이즈가 커지고, 노이즈가 커지면 정확도는 내려갈 수 있습니다.
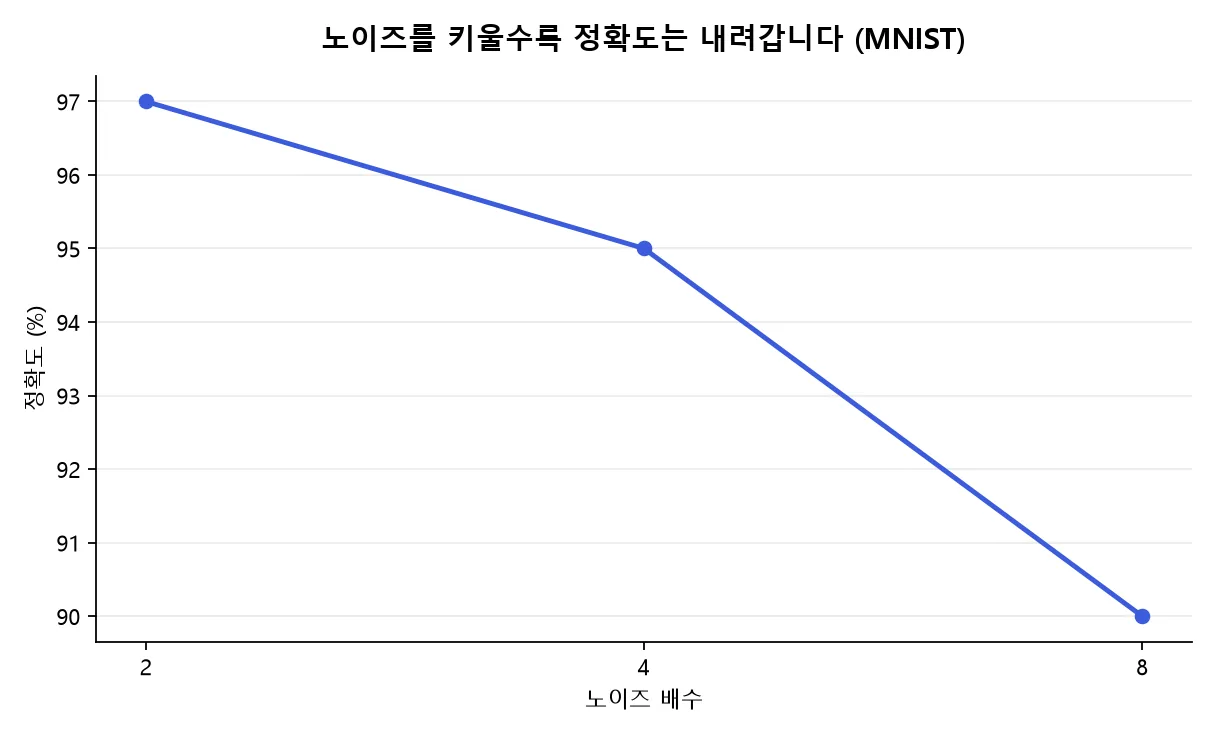
노이즈 배수 2·4·8에서 ε은 각각 8·2·0.5. 보호가 강해질수록 정확도는 떨어진다.
결국 C는 양쪽 함정을 피해야 합니다.
- 너무 작으면 신호가 잘립니다.
- 너무 크면 노이즈가 커집니다.
적응형 클리핑은 C를 자동으로 맞춥니다
그렇다면 C를 어떻게 잡아야 할까요?
손으로 찍는 방법도 있지만, 연합학습에서는 업데이트 길이가 작업마다 다릅니다. 처음에 찍은 C가 실제 분포와 맞지 않을 수 있습니다.
적응형 클리핑은 이 문제를 줄입니다. 업데이트 길이 분포의 특정 분위수, 보통 중앙값 근처에 C를 맞추도록 자동으로 조절하는 방식입니다.4
쉽게 말해 이런 방식입니다.
- 너무 많은 업데이트가 C보다 작으면 C를 줄입니다.
- 너무 많은 업데이트가 C보다 크면 C를 키웁니다.
- 기준을 업데이트 길이 분포의 가운데 근처로 따라가게 합니다.
물론 이것도 공짜는 아닙니다. C를 추정하는 과정에도 프라이버시 예산이 들어갑니다. 적응형 클리핑에서는 업데이트 합에 더하는 노이즈와 클리핑 기준 추정에 쓰는 노이즈를 분리해 설계합니다.4
그래도 장점은 큽니다. C를 감으로 찍는 대신, 실제 업데이트 분포를 보며 차등 프라이버시 방식으로 따라갑니다.
ε 보장을 깨뜨리는 흔한 실수
C를 잘못 다루면 정확도만 나빠지는 것이 아닙니다. ε 회계가 기대고 있던 전제 자체가 깨질 수 있습니다.
첫째, 자르는 순서를 바꾸는 경우입니다.
표준 DP-SGD는 샘플별 그래디언트를 계산하고, 각 그래디언트를 자르고, 그다음 합산하고, 마지막에 노이즈를 더합니다.5
순서가 중요합니다. 먼저 자르고, 합치고, 노이즈를 넣어야 합니다. 자르기 전에 평균을 내거나 샘플끼리 정보가 섞이면 ‘한 샘플의 영향이 C 이하’라는 전제가 깨질 수 있습니다.
BatchNorm처럼 배치 안에서 샘플끼리 정보를 섞는 모듈을 Opacus가 금지하는 이유도 여기에 있습니다.6
둘째, 보안 집계의 범위와 안 맞는 경우입니다.
보안 집계는 서버가 개별 클라이언트 업데이트를 보지 못하고 합계만 얻는 암호 기법입니다. 보안 집계 프로토콜은 입력과 합이 정해진 정수 범위 안에 있다고 가정합니다.7
잘린 업데이트를 이 범위에 맞게 양자화해야 합니다. 범위를 잘못 잡으면 합이 한 바퀴 돌아 잘못 계산되는 일이 생길 수 있습니다. 그러면 민감도 가정과 노이즈 회계도 함께 흔들립니다.
셋째, 표본추출 가정을 잘못 쓰는 경우입니다.
일부 회계는 ‘참여자가 무작위로 뽑혔다’는 가정 덕분에 프라이버시 손실을 더 작게 계산합니다. 그런데 연합학습에서는 매 라운드 참여 가능한 클라이언트가 시간마다 바뀝니다. 균일 표본추출을 보장하기 어렵습니다.
실제로 분산 환경에서는 균일 표본추출이나 셔플링을 보장하기 어려워서, 일부 설계는 그 증폭 효과를 아예 가정에서 뺍니다.8
프라이버시 회계가 무작위 표본추출을 가정했는데 실제 운영은 그렇지 않다면, 보고된 ε은 실제보다 낙관적일 수 있습니다.
실무에서는 이렇게 보면 됩니다
연합학습 DP-SGD에서 C를 정할 때는 아래 순서를 확인합니다.
- 보호 단위를 먼저 정합니다. 보통 한 클라이언트의 데이터 전체입니다.
- 클라이언트 업데이트 전체를 한 번 자릅니다. 한 사람의 전체 영향력을 제한해야 합니다.
- 노이즈는 C에 맞춰 넣습니다. C가 커지면 필요한 노이즈도 커집니다.
- 가능하면 적응형 클리핑을 검토합니다. 업데이트 길이 분포를 따라가면 감으로 찍는 위험을 줄일 수 있습니다.
- 보안 집계와 표본추출 가정을 확인합니다. 회계가 믿는 구조와 실제 운영이 같아야 합니다.
라이브러리 파라미터로 보면 Opacus의 max_grad_norm은 클리핑 기준 C입니다. noise_multiplier는 그 기준에 몇 배의 노이즈를 더할지 정하는 값입니다.9
목표 ε을 먼저 정하고 싶다면 Opacus의 make_private_with_epsilon처럼 목표 ε, δ, 학습 epoch 수에서 필요한 노이즈 배수를 역산하는 도구를 씁니다.9
TensorFlow Privacy도 같은 계약을 따릅니다. l2_norm_clip으로 민감도 상한을 정하고, compute_dp_sgd_privacy로 데이터 크기와 노이즈 배수, 반복 횟수, δ를 넣어 ε을 계산합니다.10
정리하면, 연합학습 DP-SGD에서 C는 단순 튜닝값이 아닙니다. 한 클라이언트가 모델을 얼마나 흔들 수 있는지 정하는 계약서입니다. 그 계약서와 노이즈 회계가 실제 학습 구조와 맞아야 ε이 말이 됩니다.
참고 문헌
Footnotes
-
Abadi, Chu, Goodfellow, McMahan, Mironov, Talwar, Zhang, ‘Deep Learning with Differential Privacy’, ACM CCS 2016. https://arxiv.org/abs/1607.00133 ↩ ↩2 ↩3
-
McMahan, Ramage, Talwar, Zhang, ‘Learning Differentially Private Recurrent Language Models’, ICLR 2018. https://arxiv.org/abs/1710.06963 ↩ ↩2
-
Kairouz, McMahan, et al., ‘Advances and Open Problems in Federated Learning’, Foundations and Trends in ML, 2021. https://arxiv.org/abs/1912.04977 ↩
-
Andrew, Thakkar, McMahan, Ramaswamy, ‘Differentially Private Learning with Adaptive Clipping’, NeurIPS 2021. https://arxiv.org/abs/1905.03871 ↩ ↩2
-
Yousefpour et al., ‘Opacus: User-Friendly Differential Privacy Library in PyTorch’, 2021. https://arxiv.org/abs/2109.12298 ↩
-
Yousefpour et al., ‘Opacus’, 2021, §2 (Model Validation). https://arxiv.org/abs/2109.12298 ↩
-
Bonawitz et al., ‘Practical Secure Aggregation for Privacy-Preserving Machine Learning’, ACM CCS 2017. https://arxiv.org/abs/1611.04482 ↩
-
Kairouz, McMahan, Song, Thakkar, Thakurta, Xu, ‘Practical and Private (Deep) Learning without Sampling or Shuffling (DP-FTRL)’, ICML 2021. https://arxiv.org/abs/2103.00039 ↩
-
Opacus 공식 API 문서, PrivacyEngine (max_grad_norm, noise_multiplier, make_private_with_epsilon). https://opacus.ai/api/privacy_engine.html ↩ ↩2
-
TensorFlow Privacy 공식 튜토리얼, ‘Implement differential privacy with TensorFlow Privacy’. https://www.tensorflow.org/responsible_ai/privacy/tutorials/classification_privacy ↩