차등 프라이버시 보호 단위: ε=1만 보고 안심하면 안 되는 이유
차등 프라이버시에서 보호 단위를 행·이벤트·사용자 중 무엇으로 잡느냐에 따라 같은 ε=1도 전혀 다른 보호가 됩니다. NIST SP 800-226의 보호 단위 논리를 수식 없이 사례로 풉니다.
정현진(Hyunjin Jeong) · 2026-06-06 · 7분 분량

‘ε=1로 보호합니다.’
이 문장만 보면 꽤 든든해 보입니다. 그런데 딱 한 가지를 빼먹으면, 이 말은 반쪽짜리 약속이 됩니다.
무엇을 하나로 보고 보호하느냐.
예를 들어 카페 거래 데이터가 632건 있다고 해 봅시다. 그중 610건이 한 단골손님의 결제 기록입니다. 이때 시스템이 ‘거래 한 건’만 보호하도록 설계돼 있다면, 그 단골손님의 생활 패턴은 제대로 보호받기 어렵습니다. 데이터 한 줄은 보호했지만, 한 사람은 보호하지 못했습니다.
차등 프라이버시에서 이 차이를 보호 단위라고 부릅니다. 영어로는 privacy unit입니다.
ε은 보호의 세기를 말합니다. 보호 단위는 그 보호가 걸리는 대상을 말합니다. ε이 자물쇠의 강도라면, 보호 단위는 그 자물쇠를 방문에 거는지, 서랍 하나에만 거는지 정하는 일입니다.
한 줄 요약: ε=1이라는 숫자만으로는 안전성을 판단할 수 없습니다. 보호 단위가 ‘한 줄’이면 한 사람이 여러 줄을 남기는 순간 보호가 약해집니다. 보호 단위를 ‘한 사람’으로 잡으려면 한 사람이 남길 수 있는 기록 수를 제한해야 하고, 그만큼 노이즈나 데이터 손실의 비용이 생깁니다. NIST가 보호 단위를 중요하게 다루는 이유가 바로 여기에 있습니다.
한 줄을 보호할 것인가, 한 사람을 보호할 것인가
차등 프라이버시의 핵심 질문은 생각보다 단순합니다.
‘이 데이터에서 무엇 하나가 빠져도 결과가 거의 같아야 하는가?’
그 ‘무엇 하나’가 보호 단위입니다.
가능한 선택지는 여러 가지입니다.
- 거래 한 건
- 접속 기록 한 건
- 설문 응답 한 줄
- 하루 동안의 사용자 기록
- 한 사람의 전체 기록
겉으로는 비슷해 보이지만 보호 강도는 크게 다릅니다.
거래 한 건을 보호하면, 한 사람이 커피를 한 번 산 사실은 보호할 수 있습니다. 하지만 그 사람이 한 달 동안 커피를 200번 샀는지는 보호하지 못할 수 있습니다.
반대로 한 사람의 전체 기록을 보호하면, 그 사람이 데이터에 있든 없든 결과가 크게 달라지지 않아야 합니다. 보호는 강해집니다. 대신 한 사람이 남긴 기록 전체를 가려야 하므로 더 많은 노이즈가 필요할 수 있습니다.
NIST SP 800-226은 차등 프라이버시 보장이 ε 같은 숫자와 보호 단위가 함께 정해진다고 설명합니다.1 ε만 적어서는 부족합니다. ‘ε=1’ 뒤에는 반드시 ‘무엇을 하나로 보호하는가’가 붙어야 합니다.
행 단위 보호가 약해지는 이유
표 계산을 떠올려 봅시다. 엑셀에서 한 줄은 거래 한 건입니다.
행 단위 보호는 이렇게 말합니다.
‘한 줄이 들어오거나 빠져도 결과가 크게 바뀌지 않게 하겠습니다.’
문제는 사람이 한 줄만 남기지 않는다는 데 있습니다. 누군가는 한 번 결제하고 끝납니다. 누군가는 매일 옵니다. 누군가는 앱을 하루에 수십 번 엽니다. 한 사람이 여러 줄로 흩어져 나타납니다.
그 상태에서 행 단위로만 보호하면, 시스템은 한 줄짜리 흔적은 가려 주지만 여러 줄로 쌓인 한 사람의 흔적은 충분히 가리지 못합니다.
차등 프라이버시에는 이 현상을 설명하는 group privacy라는 성질이 있습니다. 쉽게 말해, 한 사람이 데이터에 k번 등장하면 그 사람 관점의 보호는 대략 k배 약해질 수 있습니다.2
예를 들어 ε=1로 행 하나를 보호한다고 해도, 같은 사람이 10줄을 남겼다면 그 사람 전체를 볼 때는 ε=10 수준으로 읽힐 수 있습니다. 100줄이면 더 심각합니다. 군중 속에 한 번 등장하면 찾기 어렵지만, 같은 사람이 화면에 계속 잡히면 누구인지 보이는 것과 같습니다.
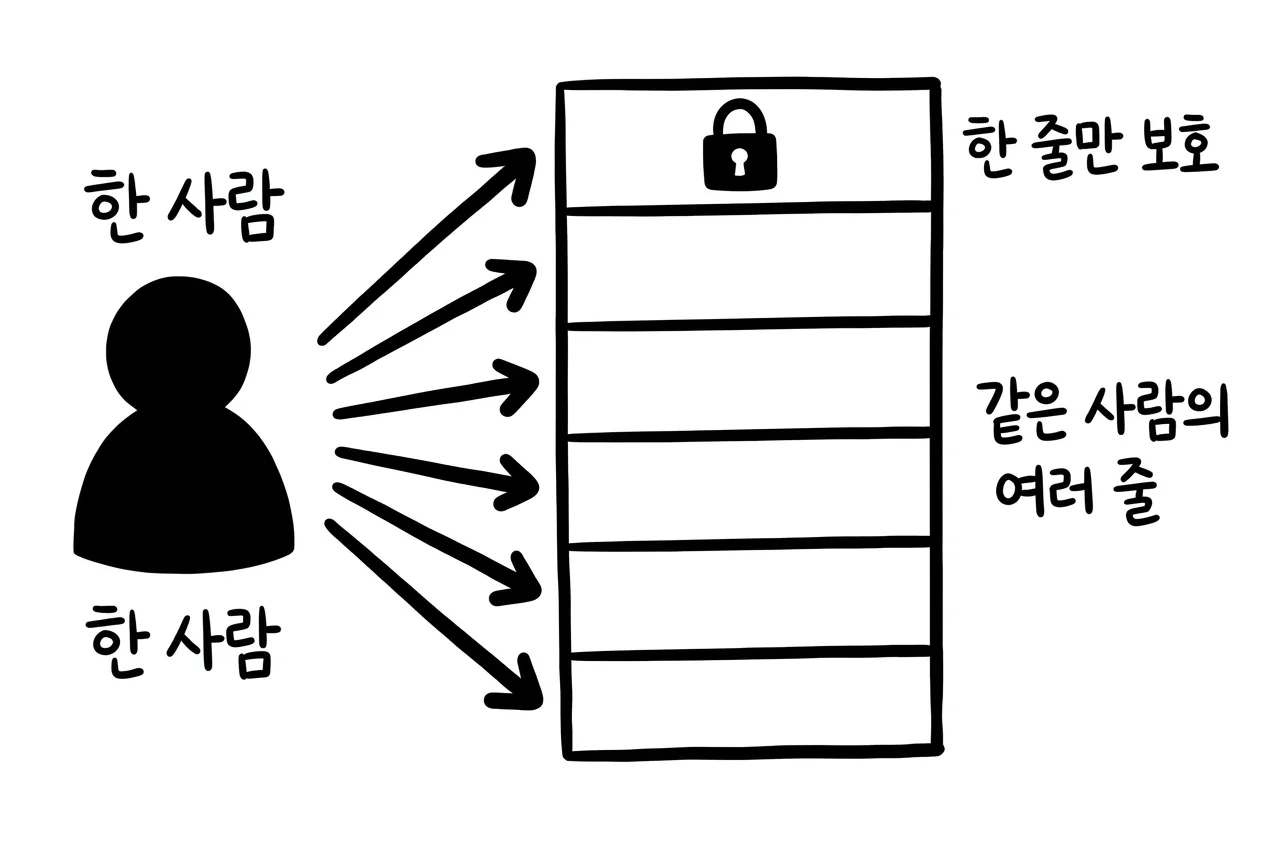
NIST의 카페 예도 이 지점을 겨냥합니다. 어떤 고객이 632건 중 610건의 거래를 차지한다면, ‘이 사람이 라떼를 많이 샀는가’ 같은 질문은 거래 한 건짜리 보호로는 막기 어렵습니다.1 거래 한 건이 아니라 그 고객의 전체 거래 묶음이 보호 대상이어야 합니다.
보호 단위를 사람으로 올리면 비용이 생깁니다
그러면 답은 간단해 보입니다.
‘처음부터 한 사람 전체를 보호하면 되잖아?’
맞습니다. 가능하면 그 방향이 더 안전합니다. NIST도 가능한 경우 최소한 한 명의 사용자만큼 큰 단위를 쓰는 쪽을 권합니다.3
하지만 여기에도 비용이 있습니다.
한 사람이 기록을 얼마나 많이 남길지 모르면, 그 사람 하나를 가리기 위해 필요한 노이즈가 끝없이 커질 수 있습니다. 그래서 실무에서는 먼저 상한을 둡니다.
‘한 사람은 최대 10건까지만 반영한다.’
‘한 사용자의 하루 기록은 최대 1번만 반영한다.’
‘한 클라이언트의 업데이트는 길이를 일정 수준에서 자른다.’
이런 절차를 기여 한정이라고 합니다. 영어로는 contribution bounding입니다. Google의 차등 프라이버시 문서도 한 개인의 기여를 제한하지 않으면 무한대의 노이즈가 필요할 수 있다고 경고합니다.4
기여 한정은 좋은 장치지만 공짜는 아닙니다.
상한을 크게 잡으면 더 많은 데이터를 살릴 수 있습니다. 대신 한 사람이 결과를 흔들 수 있는 폭이 커져서 더 많은 노이즈가 필요합니다.
상한을 작게 잡으면 노이즈는 줄일 수 있습니다. 대신 상한을 넘는 데이터는 버려야 하므로 통계가 치우칠 수 있습니다.
이 구조는 편향과 분산의 상충관계로 정리됩니다.5 한 사용자가 더 많이 기여할수록 보호에 더 많은 노이즈가 필요하고, 기여를 작게 제한하면 초과 데이터를 버리면서 편향이 생길 수 있습니다.
정리하면 이렇습니다.
보호 단위를 사람으로 올리려면, 한 사람이 남길 수 있는 영향력을 먼저 묶어야 합니다. 그 묶는 선이 높으면 노이즈가 커지고, 낮으면 데이터가 잘립니다.
이것이 차등 프라이버시 설계에서 가장 현실적인 고민입니다.
Apple 사례: 이벤트당 ε과 사용자 ε은 다릅니다
Apple의 초기 차등 프라이버시 배포는 보호 단위를 작게 잡았을 때 숫자가 어떻게 달라지는지 보여 주는 좋은 사례입니다.
Apple 공식 문서는 기능별 이벤트당 ε을 제시했습니다. 예를 들어 이모지 추천과 Safari 리소스 모니터링에서 ε=4 같은 설정값을 공개했습니다.6
이 말만 보면 ‘기능 하나, 이벤트 하나는 ε=4로 보호된다’는 뜻입니다.
그런데 사용자는 이벤트 하나로 살지 않습니다. 하루 동안 여러 기능을 쓰고, 그 데이터가 반복해서 전송될 수 있습니다. macOS 10.12 구현 분석에 따르면 서버로 제출되는 데이터 한 건당 프라이버시 손실은 ε=1 또는 2였지만, 초기 네 기능을 합치면 하루 전체 손실이 최대 16까지 올라갈 수 있었습니다.7
더 중요한 점은 예산이 매일 새로 주어졌다는 것입니다. 사용자가 차등 프라이버시 수집에 동의한 뒤 날짜가 지날수록 가능한 손실은 하루 최대 16씩 누적될 수 있습니다.7
표로 보면 차이가 선명합니다.
| 보는 기준 | Apple 사례의 값 | 읽는 법 |
|---|---|---|
| 기능별 이벤트 | ε=4 | 기능 하나의 이벤트 기준 |
| 서버 제출 1건 | ε=1 또는 2 | 실제 제출 데이터 한 건 기준 |
| 사용자 하루 | 최대 ε=16 | 초기 네 기능을 하루 단위로 합친 값 |
| 사용자 누적 기간 | 하루 최대 16씩 누적 | 매일 예산이 새로 주어질 때의 누적 |
위쪽 숫자만 보면 작아 보입니다. 아래쪽으로 내려가 사용자 관점에서 보면 훨씬 커집니다.
이 사례의 교훈은 Apple이 나쁘다는 식의 단순한 이야기가 아닙니다. ε은 반드시 보호 단위와 기간을 함께 봐야 한다는 것입니다.
‘이벤트당 ε=4’와 ‘사용자 하루 최대 ε=16’은 같은 말이 아닙니다.
사용자-하루 단위도 조심해야 합니다
사용자 전체가 너무 크다고 해서 ‘사용자-하루’를 보호 단위로 잡는 경우가 있습니다. 하루 단위로는 그럴듯해 보입니다.
‘오늘 하루 한 사용자의 기록은 보호한다.’
그런데 이 예산이 매일 새로 시작되면 어떻게 될까요?
하루 ε=1이면 1년 동안 단순 합산으로 ε=365가 될 수 있습니다. NIST도 사용자-하루 단위 보호가 장기간 누적될 때 약해질 수 있음을 경고합니다.3
다시 말해, ‘하루 동안 안전하다’와 ‘사용자 전체 생애에 걸쳐 안전하다’는 전혀 다른 말입니다. 서비스가 매일 데이터를 모은다면, 보호 단위와 함께 누적 기간도 반드시 적어야 합니다.
실무에서는 이렇게 물어야 합니다
보호 단위를 정할 때는 수식부터 꺼낼 필요가 없습니다. 아래 질문부터 던지면 됩니다.
- 공격자가 알고 싶어 하는 것은 무엇인가?
- 그 정보는 데이터에서 한 줄로 나타나는가, 여러 줄로 나타나는가?
- 한 사람이 남길 수 있는 기록 수나 영향력을 어디까지 인정할 것인가?
- 그 상한을 넘는 데이터는 버릴 것인가, 더 큰 노이즈를 넣을 것인가?
- 예산은 하루마다 새로 주는가, 사용자 전체 기간으로 누적하는가?
카페 예로 다시 보겠습니다.
공격자가 알고 싶은 것이 ‘이 사람이 오늘 라떼 한 잔을 샀는가’라면 거래 한 건 보호가 어느 정도 의미를 가질 수 있습니다.
하지만 공격자가 알고 싶은 것이 ‘이 사람이 라떼를 200잔 넘게 샀는가’라면 거래 한 건 보호로는 부족합니다. 그 사람의 거래 묶음 전체를 보호해야 합니다.
BigQuery의 차등 프라이버시 기능도 이 선택을 코드에 드러냅니다. privacy_unit_column이라는 옵션으로 보호 단위를 나타내는 컬럼을 지정합니다.8 결국 ‘어느 컬럼이 한 사람을 나타내는가’를 시스템에 알려 줘야 합니다.
미국 인구조사국의 2020 Census TopDown Algorithm도 보호 단위를 명시적으로 다루는 대규모 사례입니다. 국가 통계처럼 큰 배포일수록 ‘무엇이 한 단위인가’를 흐리게 둘 수 없습니다.9
결론: ε을 볼 때는 뒤에 붙은 단위를 같이 보세요
차등 프라이버시 글이나 제품 설명에서 ‘ε=1’을 봤다면, 바로 다음 질문은 이것이어야 합니다.
무엇 하나를 보호해서 ε=1인가?
한 줄인가요?
한 번의 이벤트인가요?
하루 동안의 사용자 기록인가요?
한 사람의 전체 기록인가요?
이 질문에 답하지 못하면 ε 숫자는 반쪽짜리입니다. 행 단위 ε=1은 한 사람이 한 줄만 남길 때는 그럴듯하지만, 한 사람이 수십·수백 줄을 남기면 사용자 보호로 바로 읽을 수 없습니다.
좋은 차등 프라이버시 설명은 이렇게 적혀야 합니다.
ε=1, 보호 단위: 사용자, 기여 상한: 사용자당 최대 10건, 누적 기간: 1년
이 정도는 적어야 ‘무엇을 얼마나 보호하는지’가 보입니다.
ε은 보호의 세기입니다. 보호 단위는 그 세기가 걸리는 대상입니다. 둘을 같이 봐야 차등 프라이버시가 진짜 약속이 됩니다.
참고 문헌
Footnotes
-
Near, J., Darais, D., Lefkovitz, N., Howarth, G. Guidelines for Evaluating Differential Privacy Guarantees — NIST SP 800-226, March 2025. §2.1.1 Key Takeaway / §2.4.2 Event Level. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2
-
Dwork, C., Roth, A. The Algorithmic Foundations of Differential Privacy, 2014. Definition 2.4 (§2.3, p.18) / Theorem 2.2 group privacy (§2.3, p.20). https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
Near, J., Darais, D., Lefkovitz, N. NIST SP 800-226, §2.4.2 ‘Evaluating the Unit of Privacy’ / Key Takeaway, March 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2
-
Google Differential Privacy Team. differential_privacy.md — Privacy Unit / Contribution Bounding, google/differential-privacy. https://github.com/google/differential-privacy/blob/main/differential_privacy.md ↩
-
Amin, K., Kulesza, A., Medina, A. M., Vassilvitskii, S. Bounding User Contributions: A Bias-Variance Trade-off in Differential Privacy, ICML 2019 (Google Research). https://research.google/pubs/bounding-user-contributions-a-bias-variance-trade-off-in-differential-privacy/ ↩
-
Apple Differential Privacy Team. Learning with Privacy at Scale, Apple Machine Learning Research, 2017. https://machinelearning.apple.com/research/learning-with-privacy-at-scale ↩
-
Tang, J., Korolova, A., Bai, X., Wang, X., Wang, X. Privacy Loss in Apple's Implementation of Differential Privacy on MacOS 10.12, arXiv:1709.02753, 2017. https://arxiv.org/abs/1709.02753 ↩ ↩2
-
Google Cloud. Use differential privacy — BigQuery DP documentation. https://docs.cloud.google.com/bigquery/docs/differential-privacy ↩
-
Abowd, J. M. et al. The 2020 Census Disclosure Avoidance System TopDown Algorithm, arXiv:2204.08986 (Census WP CED-WP-2022-002), 2022. https://arxiv.org/abs/2204.08986 ↩