DP로 인원을 세면 음수가 나오는 이유: 버그가 아니라 노이즈입니다
차등 프라이버시로 인원을 셀 때 음수가 나오는 이유와, 0으로 자를 때 생기는 편향을 수식보다 직관과 실무 판단 기준으로 설명합니다.
정현진(Hyunjin Jeong) · 2026-06-09 · 4분 분량

헬스케어 데이터 분석 팀이 차등 프라이버시 라이브러리를 처음 붙였다고 해 봅시다. 질문은 단순합니다.
‘작년에 이 병원에서 당뇨 진단을 받은 환자는 몇 명인가?’
ε=0.1로 환자 수를 뽑았더니 화면에 -3.7이 찍혔습니다.
환자 수가 음수라니, 누가 봐도 이상합니다. 첫 반응은 대개 이렇습니다.
‘라이브러리 버그 아닌가?’
결론부터 말하면, 아닙니다. 라플라스 메커니즘에서는 결과가 음수로 나오는 것도 정상입니다.
한 줄 요약: 차등 프라이버시는 참값에 노이즈를 더합니다. 그 노이즈는 위로도, 아래로도 흔들리기 때문에 참값이 작으면 음수가 나올 수 있습니다. 0보다 작은 값을 0으로 자르면 ε 보장은 깨지지 않지만, 통계는 위로 치우칠 수 있습니다. 화면 표시용과 분석용 후처리는 구분해야 합니다.
NIST 공식 용어집은 라플라스 메커니즘을 쿼리 결과에 라플라스 분포에서 뽑은 무작위 노이즈를 더하는 차등 프라이버시 기본 부품으로 정의합니다.1 이 정의에는 ‘출력은 반드시 0 이상이어야 한다’는 조건이 없습니다.
라플라스 메커니즘은 무한한 범위를 가지므로 음수처럼 의미상 불가능한 값도 반환할 수 있습니다.2
OpenDP의 make_laplace 역시 노이즈를 더한다고 설명할 뿐, 음수가 안 나오게 잘라 준다고 말하지 않습니다.3
즉, -3.7은 계산 실패가 아닙니다. ‘참값 + 아래로도 흔들릴 수 있는 노이즈’의 결과입니다.
환자 수가 음수로 나오는 원리
라플라스 노이즈는 0을 중심으로 좌우 대칭입니다.
위로 흔들릴 수도 있고, 아래로 흔들릴 수도 있습니다. 참값이 1명, 2명, 5명처럼 작으면 아래로 조금만 크게 흔들려도 결과가 0 밑으로 내려갑니다.
사람 수를 세는 쿼리에서는 보통 한 사람이 들어오거나 빠질 때 결과가 최대 1만 바뀝니다. 그래서 보호를 강하게 걸수록, 즉 ε을 작게 잡을수록 더 큰 노이즈를 넣습니다.
감으로 보면 이렇습니다.
| 참값 | ε | 음수 출력 가능성 |
|---|---|---|
| 5 | 1.0 | 약 300번에 1번 |
| 5 | 0.5 | 약 25번에 1번 |
| 5 | 0.1 | 약 3번에 1번 |
ε=0.1처럼 보호를 강하게 걸면 참값이 5일 때도 세 번에 한 번꼴로 음수가 나올 수 있습니다. 직관에는 어색하지만, 노이즈 분포 입장에서는 자연스러운 결과입니다.
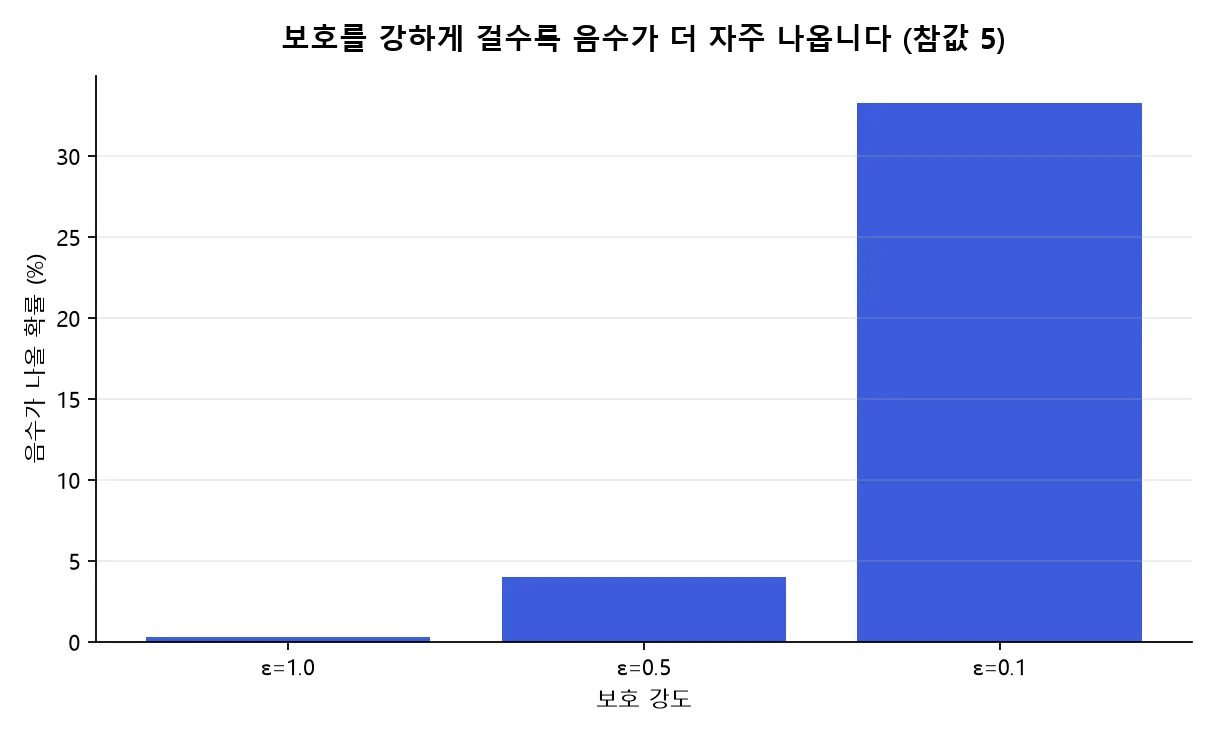
참값이 5일 때 결과가 음수로 나올 대략적 빈도. ε=0.1이면 세 번에 한 번꼴.
실제 라이브러리 예시도 같은 흐름입니다. OpenDP의 typical workflow 튜토리얼은 수를 세는 예제에서 scale = 3.0, accuracy = 9.44를 보여 줍니다.4 참값이 작으면 음수가 충분히 나올 수 있는 수준입니다.
Google의 오픈소스 차등 프라이버시 라이브러리도 Count 알고리즘에서 노이즈를 더한 값을 그대로 반환합니다. 0 밑을 자동으로 자르는 단계는 없습니다.5
0으로 자르면 프라이버시 보장은 그대로입니다
그렇다고 대시보드에 환자 수 -3.7명을 그대로 보여 줄 수는 없습니다. 가장 쉬운 처리는 0보다 작은 값을 0으로 바꾸는 것입니다.
displayCount = Math.max(0, noisyCount)
이 처리를 0 자르기라고 부르겠습니다. 논문에서는 clip-to-zero 또는 boundary-inflated truncation이라는 표현을 씁니다.
중요한 점이 있습니다. 0 자르기는 차등 프라이버시 보장을 깨지 않습니다.
이유는 간단합니다. 이미 나온 숫자만 보고 처리하기 때문입니다. 원본 데이터를 다시 들여다보지 않습니다.
차등 프라이버시에는 후처리 불변성이라는 성질이 있습니다. DP 메커니즘이 내놓은 결과에 원본 데이터와 무관한 계산을 더해도 프라이버시 손실은 늘어나지 않습니다.6
따라서 화면 표시를 위해 max(0, x)를 적용해도 ε 예산을 새로 쓰지는 않습니다.
하지만 여기서 끝내면 반쪽 답입니다. 프라이버시는 괜찮아도, 통계는 망가질 수 있습니다.
0으로 자르면 평균이 위로 뜹니다
라플라스 노이즈는 평균 0입니다. 위로 흔들린 오차와 아래로 흔들린 오차가 장기적으로 상쇄됩니다.
그런데 아래로 내려간 값만 0에서 잘라 버리면 어떻게 될까요?
음수 오차는 사라지고, 양수 오차는 그대로 남습니다. 결과의 평균이 위로 뜹니다. 이것이 양의 편향입니다.
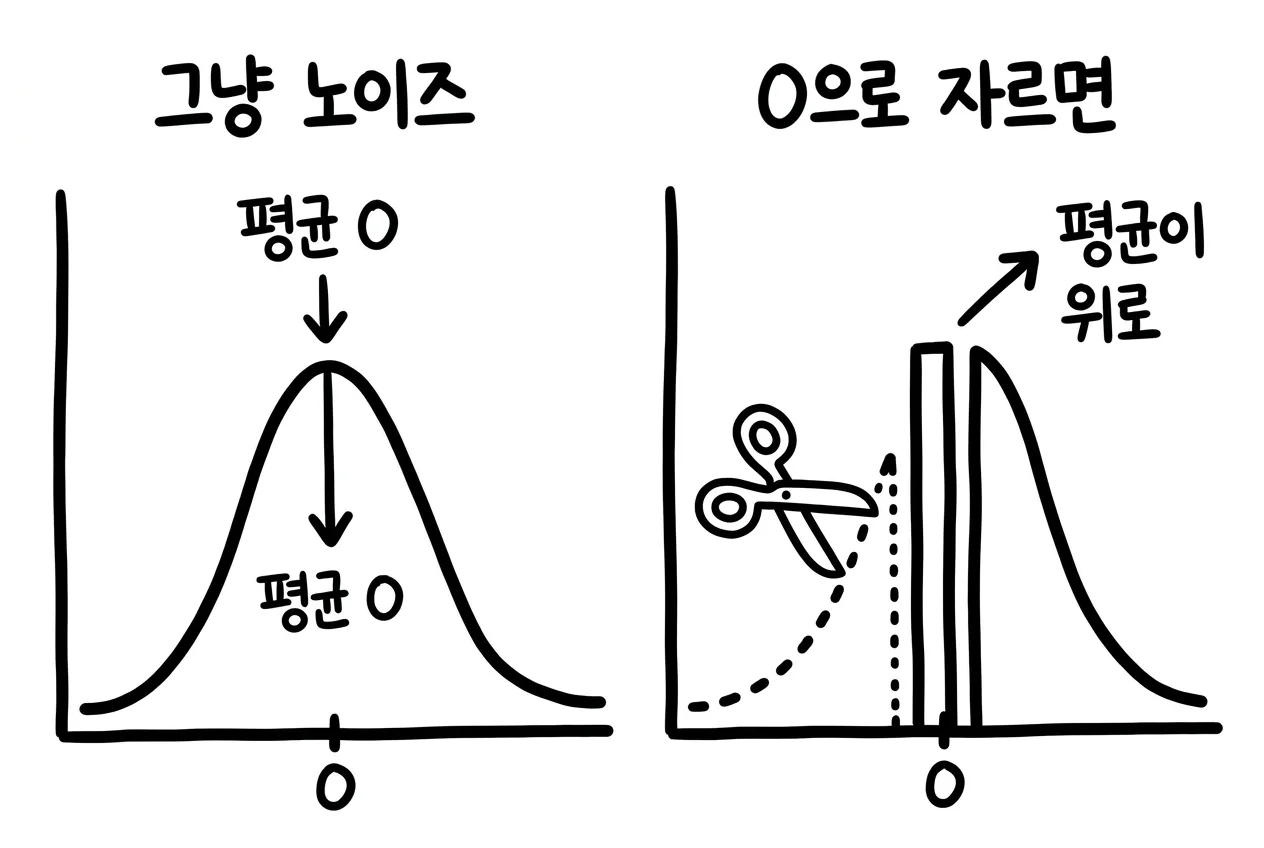
라플라스 메커니즘 출력에 0 자르기를 적용하면 엄격한 양의 편향이 발생한다는 것이 수학적으로 증명돼 있습니다.7
작은 값이 많을수록 문제가 커집니다. 예를 들어 지역별 희귀질환 환자 수, 세부 진단명별 건수, 연령×성별×지역 표처럼 셀이 잘게 쪼개진 통계에서는 음수가 자주 나옵니다.
이 값을 모두 0으로 자르면 각 셀의 작은 편향이 합계와 비율로 쌓입니다.
ε이 작을수록 노이즈가 커지고, 음수도 더 자주 나옵니다. 그러면 0 자르기가 더 자주 발동하고, 편향도 커집니다.
화면 표시와 분석용 데이터는 다르게 봐야 합니다
화면 표시용 숫자라면 0 자르기가 실용적일 수 있습니다.
‘대시보드에 음수 환자 수를 보여 주지 않는다.’
이 정도 목적이면 괜찮습니다.
하지만 그 값을 다시 더하거나, 비율을 계산하거나, 지역-시도-전국처럼 계층 합계를 맞춰야 한다면 단순히 0으로 자르는 것은 위험합니다.
값이 음수가 아니어야 하고 합도 맞아야 한다는 제약을 만족하는 사후 추정을 쓰면 같은 ε에서도 정확도를 높일 수 있습니다.8
미국 2020 센서스의 TopDown 알고리즘도 노이즈가 섞인 값을 그대로 공개하지 않았습니다. 값을 음수가 아니게, 정수로, 계층 합이 맞게 강제하는 대규모 후처리를 적용했습니다. 다만 외부 평가에서는 이런 후처리가 인구가 적은 지역에서 체계적인 양의 편향을 만들고, 주 인구 합 같은 불변값이 고정된 큰 지역에서는 반대로 음의 편향을 만들 수 있다는 점이 확인됐습니다.9
교훈은 분명합니다.
‘0 밑은 잘라요’는 화면에서는 간단합니다. 하지만 통계표 전체에서는 간단하지 않습니다.
실무 판단 기준
결과가 음수로 나왔을 때는 이렇게 판단하는 편이 안전합니다.
- 먼저 음수 발생 빈도를 예상합니다. 참값이 작고 ε이 작으면 음수는 꽤 자주 나옵니다.
- 화면 표시인지 분석용인지 나눕니다. 보여 주기만 할 값이면 0 자르기가 실용적일 수 있습니다.
- 합계·비율·계층 표에는 단순 0 자르기를 피합니다. 일관성 후처리나 계층 제약을 검토합니다.
- ε 조정도 정직한 선택입니다. 정책상 허용된다면 ε을 키워 노이즈와 음수 발생 빈도를 낮출 수 있습니다. 물론 보호는 그만큼 약해집니다.
가장 위험한 선택은 ‘음수가 나왔네? 그냥 0으로 자르자’입니다. ε 보장은 그대로일 수 있습니다. 하지만 통계는 조용히 위로 떠 있을 수 있습니다.
참고 문헌
Footnotes
-
NIST Computer Security Resource Center, Glossary entry ‘Laplace mechanism’ (source: NIST SP 800-226), 2025. https://csrc.nist.gov/glossary/term/laplace_mechanism ↩
-
Holohan, Antonatos, Braghin, Mac Aonghusa, ‘The Bounded Laplace Mechanism in Differential Privacy,’ arXiv:1808.10410, 2018. https://arxiv.org/abs/1808.10410 ↩
-
OpenDP Library,
opendp.measurements.make_laplaceAPI reference (Harvard/MIT/Microsoft OpenDP Project). https://docs.opendp.org/en/stable/api/python/opendp.measurements.html ↩ -
OpenDP ‘Typical workflow’ getting-started guide — count query example. https://docs.opendp.org/en/stable/getting-started/typical-workflow.html ↩
-
google/differential-privacy GitHub —
cc/algorithms/count.h(Count algorithm header). https://github.com/google/differential-privacy/blob/main/cc/algorithms/count.h ↩ -
OpenDP Documentation, ‘A Framework to Understand DP’ — Distance Between Distributions / Divergence section. https://docs.opendp.org/en/stable/theory/a-framework-to-understand-dp.html ↩
-
McGlinchey & Mason, ‘Observations on the Bias of Nonnegative Mechanisms for Differential Privacy,’ AIMS Foundations of Data Science, 2020 / arXiv:2101.02957. https://arxiv.org/abs/2101.02957 ↩
-
Hay, Rastogi, Miklau, Suciu, ‘Boosting the Accuracy of Differentially-Private Histograms Through Consistency,’ VLDB 2010 / arXiv:0904.0942. https://arxiv.org/abs/0904.0942 ↩
-
Kenny, Kuriwaki, McCartan, Rosenman, Simko, Imai, ‘Evaluating Bias and Noise Induced by the U.S. Census Bureau's Privacy Protection Methods,’ Science Advances, 2024 / arXiv:2306.07521. https://arxiv.org/abs/2306.07521v2 ↩