차등 프라이버시가 부정확해지는 세 가지 이유: 통계·정보·측정의 벽
차등 프라이버시가 실제로 부정확해지는 이유를 통계의 벽, 정보의 벽, 측정의 벽으로 나눠 설명합니다. 무엇이 DP 고유의 한계이고 무엇이 아닌지 쉽게 풉니다.
정현진(Hyunjin Jeong) · 2026-06-14 · 9분 분량
차등 프라이버시를 처음 써 본 사람이 가장 자주 하는 말이 있습니다.
‘노이즈를 넣었더니 결과가 못 쓰겠던데요?’
맞는 말일 때가 있습니다. 하지만 여기서 바로 ‘차등 프라이버시는 부정확하다’로 뛰면 진단이 틀어집니다. 정확도가 안 나오는 이유가 하나가 아니기 때문입니다.
차등 프라이버시에는 세 가지 벽이 겹쳐 있습니다.
- 통계의 벽: 원래 추정하려던 값 자체가 불안정합니다.
- 정보의 벽: 프라이버시를 지키는 대가로 정확도에 증명된 하한이 있습니다.
- 측정의 벽: 정확한지 확인하는 일조차 추가 프라이버시를 씁니다.
셋 중 차등 프라이버시 고유의 한계는 두 번째, 정보의 벽입니다. 첫 번째는 통계학이 오래전부터 안고 있던 문제이고, 세 번째는 차등 프라이버시가 특히 선명하게 드러내는 검증의 문제입니다.
한 줄 요약: 차등 프라이버시가 부정확해 보일 때는 먼저 어느 벽인지 나눠야 합니다. 평균 자체가 불안정한 문제는 DP를 바꿔도 해결되지 않습니다. 반대로 프라이버시 때문에 추가로 생기는 오차는 이론적 하한이 있어 마음대로 줄일 수 없습니다. 마지막으로, 출력이 실제로 얼마나 쓸 만한지 검증하는 일도 같은 민감 데이터에서는 공짜가 아닙니다.
차등 프라이버시가 약속하는 것
용어부터 짧게 정리하겠습니다.
차등 프라이버시는 어떤 결과를 보고 특정 개인이 데이터에 있었는지 알아내는 능력에 ε(엡실론)이라는 상한을 씌우는 기법입니다.
NIST SP 800-226도 차등 프라이버시를 개인의 데이터가 데이터셋에 있을 때 생기는 프라이버시 손실을 정량화하는 수학적 프레임워크로 설명합니다.1
예를 들어 회사가 평균 연봉을 발표한다고 합시다. 공격자는 이렇게 묻습니다.
‘김 부장이 평균 계산에 들어갔나?’
차등 프라이버시는 평균을 못 내게 하는 기술이 아닙니다. 평균은 공개하되, 그 평균만 보고 김 부장의 포함 여부를 확신하기 어렵게 만듭니다.
문제는 여기서 시작됩니다. 개인 흔적을 가리려면 노이즈가 필요합니다. 그러면 정확도가 흔들립니다. 그런데 그 흔들림이 전부 차등 프라이버시 탓은 아닙니다.
벽 1: 통계의 벽
먼저 차등 프라이버시와 별개로, 통계 자체가 어려운 경우가 있습니다.
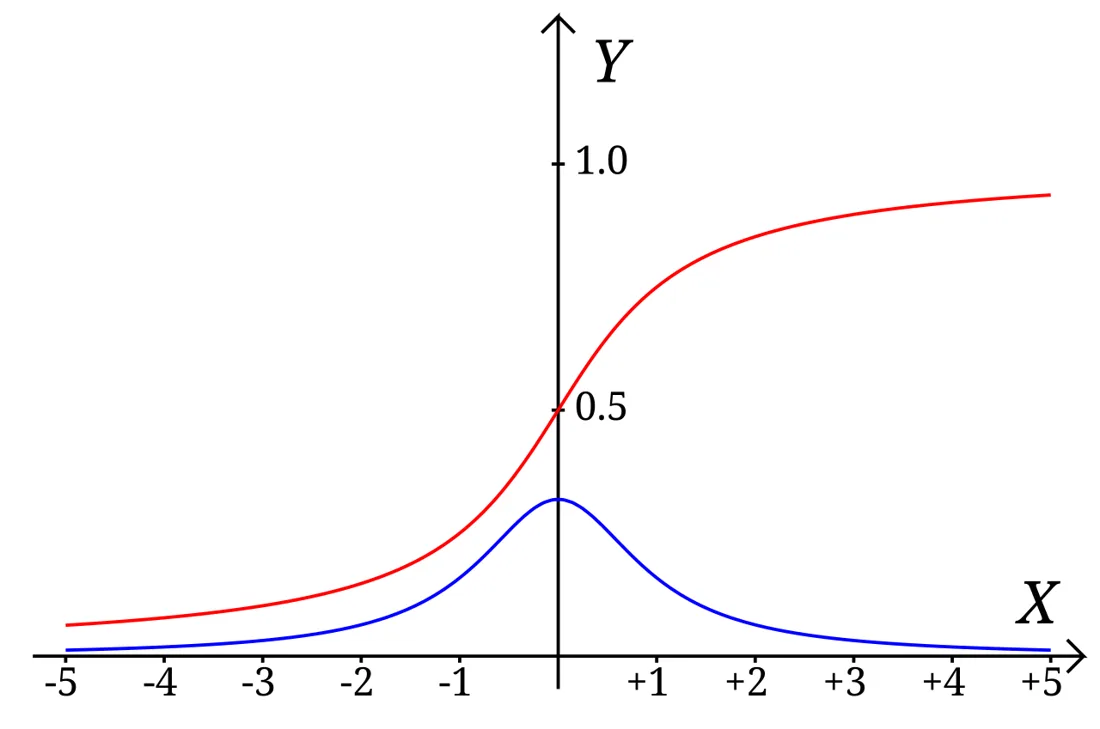
대표 사례가 코시(Cauchy) 분포입니다. 생긴 것은 종 모양이지만 꼬리가 아주 두껍습니다. 실제로 코시 분포의 평균과 표준편차는 수학적으로 정의되지 않으며, 1,000개 데이터를 모아도 평균 추정이 한 점으로 안정되지 않습니다.2
이 상황에서 ‘평균을 정확히 맞히라’고 요구하면 출발부터 이상합니다. 평균이라는 목표물이 제대로 서 있지 않기 때문입니다.
이미지 출처: Lieven Smits · CC BY-SA 3.0 — Wikimedia Commons
{kind=link}
파레토(Pareto) 분포도 조심해야 합니다. 꼬리 지수 α가 1보다 크고 2보다 작으면 평균은 존재하지만 분산은 무한입니다. 즉 평균은 말할 수 있지만, 표본평균이 보통 데이터처럼 차분하게 안정되지 않습니다. 반대로 α가 1 이하라면 평균 자체도 유한하지 않습니다.
여기서 차등 프라이버시의 입장은 냉정합니다.
노이즈를 0으로 줄여도 비공개 추정이 불안정하다면, 차등 프라이버시 버전도 그 한계를 물려받습니다.
오히려 차등 프라이버시는 한 가지 부담을 더 집니다. 한 사람이 결과를 무한정 흔들 수 있으면 프라이버시를 보장할 수 없기 때문에, 실무에서는 값을 일정 범위 안으로 잘라내야 합니다. 이를 클리핑 또는 절단이라고 부릅니다.
하지만 두꺼운 꼬리를 자르면 평균이 치우칠 수 있습니다. 자르지 않으면 노이즈가 커지고, 자르면 편향이 생깁니다. 두꺼운 꼬리 분포의 비공개 평균 추정에서 표본 수와 정확도의 상충은 이미 이론적으로 분석된 핵심 문제입니다.3
이 벽의 처방은 ‘더 멋진 DP 메커니즘’이 아닙니다. 추정 대상을 바꿔야 합니다. 평균이 위험하면 중앙값, 절단 평균, 분위수처럼 더 안정적인 값을 검토해야 합니다.
차등 프라이버시를 욕할 문제가 아닙니다. 애초에 체중계 위에 바람 부는 풍선을 올려놓고 ‘왜 숫자가 흔들리냐’고 묻는 상황에 가깝습니다.
벽 2: 정보의 벽
두 번째가 진짜 차등 프라이버시의 벽입니다.
프라이버시를 지키면 정확도에 비용이 생깁니다. 이 비용은 단순한 감이 아니라 정리로 증명됩니다. 차등 프라이버시의 표준 교과서도 여러 기본 질의에서 프라이버시 보장과 정확도 사이의 하한을 다룹니다.4
가장 쉬운 예는 0부터 1까지의 값으로 된 데이터의 평균입니다. 사람 수가 n명이고 보호 강도가 ε이라면, 경험적 평균을 차등 프라이버시로 공개할 때 프라이버시 때문에 추가되는 오차는 대략 1을 n 곱하기 ε으로 나눈 크기 밑으로 내려가기 어렵습니다.
말을 더 풀면 이렇습니다.
- 사람이 많아지면 오차가 줄어듭니다.
- ε을 크게 잡아 보호를 느슨하게 하면 오차가 줄어듭니다.
- 사람이 적고 ε도 작으면, 어떤 영리한 알고리즘을 써도 오차를 마음대로 줄일 수 없습니다.
라플라스 메커니즘이 이 간단한 평균 문제에서 이미 같은 크기 수준의 오차를 냅니다. 그래서 ‘더 똑똑한 비밀 알고리즘을 쓰면 노이즈를 거의 없앨 수 있다’는 식의 말은 조심해야 합니다. 상수배나 조건 차이는 있을 수 있지만, 경계 자체를 없앨 수는 없습니다.
고차원에서는 비용이 더 무겁습니다. 좌표가 하나일 때와 100개일 때는 같은 문제가 아닙니다. 선형 질의에 필요한 노이즈의 크기는 질의의 기하학적 구조에 따라 달라집니다.5 순수 ε-DP와 조금 약한 (ε, δ)-DP 사이의 차이도 이 관점에서 분명해집니다.
개략적으로 보면 이렇습니다.
| 상황 | 정확도에 붙는 비용의 느낌 | 읽는 법 |
|---|---|---|
| 1차원 평균 | 1을 사람 수와 ε으로 나눈 크기 | 라플라스가 거의 기본선 |
| 여러 좌표 평균, 순수 ε-DP | 차원 수가 직접 부담으로 붙을 수 있음 | 좌표가 많을수록 노이즈 부담 증가 |
| 여러 좌표 평균, (ε, δ)-DP | 차원 수의 제곱근 정도로 줄어드는 설정이 있음 | δ를 허용해 정확도를 사는 구조 |
| 많은 질의에 동시에 답하기 | 표본 수가 감당할 수 있는 질의 수에 천장 | 같은 데이터에서 답을 무한정 뽑을 수 없음 |
여기서 중요한 표현은 ‘설정이 있음’입니다. 오차 기준, 질의 구조, 프라이버시 정의에 따라 정확한 하한은 달라집니다. 다만 큰 방향은 같습니다. 차원이 늘고 질의가 늘면 프라이버시 비용도 같이 늘어납니다.
질의가 아주 많아질 때는 핑거프린팅 하한이 등장합니다. 핑거프린팅 코드를 이용한 정보이론적 하한 연구에 따르면, 수를 세는 질의 여러 개에 동시에 정확히 답하려면 표본 수가 충분히 커야 합니다.6
직관은 간단합니다.
같은 데이터셋에서 정확한 답을 끝없이 뽑아낼 수는 없습니다.
이것이 정보의 벽입니다. 좋은 메커니즘은 이 벽에 가까이 갈 뿐, 통과하지 못합니다. 누군가 ‘프라이버시는 그대로인데 오차는 거의 없다’고 말한다면 둘 중 하나를 의심해야 합니다. 회계가 틀렸거나, 보호 모델이 새고 있을 가능성이 큽니다.
δ는 공짜 쿠폰이 아닙니다
정보의 벽을 이야기할 때 δ(델타)를 빼놓으면 안 됩니다.
순수 ε-DP는 δ가 0인 보장입니다. 반면 (ε, δ)-DP는 아주 작은 예외 확률 δ를 허용합니다. 그 대신 가우시안 노이즈 같은 더 유용한 메커니즘을 쓸 수 있고, 고차원 문제에서 정확도가 좋아지는 경우도 있습니다.
하지만 δ는 단순한 장식 숫자가 아닙니다.
δ는 그 작은 확률 안에서 ε 보장이 통째로 깨질 수 있음을 뜻합니다. NIST도 δ가 데이터 크기의 역수보다 크면 위험하다고 경고합니다.1
환자 1,000명 데이터에서 δ를 0.001로 잡았다고 합시다. 0.001은 1,000명 중 한 명꼴입니다. 이 정도 크기라면 ‘환자 한 명의 기록이 통째로 드러나는 사건’도 아주 드문 예외라는 이름으로 밀어 넣을 수 있습니다.
그러니 δ는 공짜 쿠폰이 아닙니다. 정확도를 사는 대신 아주 작은 파국 확률을 허용하는 계약입니다. 그 확률이 충분히 작은지 반드시 따져야 합니다.
예산은 한 번 쓰면 줄어듭니다
실무에서 부딪히는 벽이 하나 더 있습니다. 바로 프라이버시 예산입니다.
같은 데이터에 쿼리를 반복하면 ε이 누적됩니다. 합성 정리는 여러 차등 프라이버시 메커니즘을 함께 공개할 때 전체 보장이 어떻게 쌓이는지 설명합니다.4 NIST도 프라이버시 예산을 하나의 데이터셋을 처리하는 모든 분석에 걸친 누적 손실의 허용 상한으로 정의합니다.1
분석가 입장에서는 답답할 수 있습니다.
‘한 번 더 물어보면 안 되나?’
질문은 할 수 있습니다. 다만 비용을 냅니다. 통장에서 돈을 쓰면 잔고가 줄듯, 같은 데이터에 답을 계속 요구하면 남은 프라이버시 여유가 줄어듭니다.
학습이 끝난 모델은 추론을 계속 돌릴 수 있습니다. 하지만 원본 민감 데이터에 차등 프라이버시 질의를 던지는 과정은 수명이 있습니다. 예산 장부 없이 운영하면, 어느 순간 ‘ε=1로 보호했다’는 말이 더 이상 맞지 않게 됩니다.
벽 3: 측정의 벽
세 번째 벽은 덜 알려졌지만 실무에서는 아주 중요합니다.
차등 프라이버시 결과를 받았습니다. 이 숫자가 얼마나 정확한지 어떻게 확인할까요?
참값과 비교하면 됩니다. 그런데 그 참값이 같은 민감 데이터에서 나온다면, 참값을 보는 행위도 정보 접근입니다. 경우에 따라 검증 자체가 추가 프라이버시 예산을 써야 합니다.
물론 모든 검증이 불가능하다는 뜻은 아닙니다. 공개 데이터, 합성 데이터, 별도 동의로 확보한 평가 데이터, 이미 공개 가능한 집계값이 있다면 그것으로 테스트할 수 있습니다. 문제는 같은 보호 대상 데이터에서 공짜로 참값을 꺼내 검산할 수는 없다는 점입니다.
머신러닝에서 흔한 홀드아웃 검증도 조심해야 합니다. 검증 세트를 한두 번 쓰는 것과, 결과를 보고 계속 다시 쓰는 것은 다릅니다. 적응적으로 반복되는 데이터 분석에서 통계적 타당성이 무너지는 문제를 연구한 결과, 차등 프라이버시 기법이 이런 재사용 위험을 제어하는 데 효과적임이 밝혀졌습니다.7
즉 차등 프라이버시는 이런 비대칭을 만듭니다.
- ‘이 메커니즘이 ε-DP다’는 증명할 수 있습니다.
- ‘이번 출력이 업무에 충분히 정확하다’는 별도 검증 설계가 필요합니다.
프라이버시는 수학으로 보증되지만, 효용은 운영 맥락에서 확인해야 합니다. 그리고 그 확인도 민감 데이터를 다시 보면 비용이 듭니다.
정확도 메트릭도 함정입니다
정확도를 측정할 때 빠지기 쉬운 함정이 하나 더 있습니다. 무엇을 정확하다고 부를지에 따라 결론이 바뀝니다.
예를 들어 실제로 2명인데 차등 프라이버시 결과가 4명으로 나왔다고 합시다. 절대오차는 2명입니다. 그런데 상대오차는 100%입니다.
반대로 참값이 1,000,000명인데 결과가 999,998명이라면 절대오차는 똑같이 2명입니다. 하지만 상대오차는 거의 0에 가깝습니다.
어떤 메트릭을 쓰느냐에 따라 같은 오차가 심각해 보이기도 하고 사소해 보이기도 합니다.
| 메트릭 | 장점 | 조심할 점 |
|---|---|---|
| 절대오차 | 사람이 바로 이해하기 쉬움 | 큰 집단과 작은 집단을 같은 자로 재기 어려움 |
| 상대오차 | 규모가 다른 집단을 비교하기 좋음 | 참값이 0 근처면 폭발 |
| 전체 합계 오차 | 큰 그림을 보기 좋음 | 작은 셀의 실패를 숨길 수 있음 |
| 작은 셀 정확도 | 희소 집단 보호를 점검하기 좋음 | 노이즈 영향이 크게 보임 |
그래서 ‘차등 프라이버시가 부정확하다’는 말은 항상 반쪽입니다.
어떤 값에서, 어떤 메트릭으로, 어떤 사용 목적에 대해 부정확한지까지 말해야 합니다. 지도 전체 추세를 보려는 목적과 희귀질환 소지역 통계를 보려는 목적은 같은 정확도 기준을 쓸 수 없습니다.
세 벽의 처방은 다릅니다
세 벽을 한 표로 정리하면 이렇습니다.
| 벽 | 무엇이 문제인가 | DP 고유 한계인가 | 처방 |
|---|---|---|---|
| 통계의 벽 | 추정 대상 자체가 불안정 | 아니오 | 평균 대신 중앙값·절단 평균·분위수 검토 |
| 정보의 벽 | 프라이버시 때문에 증명된 오차 하한이 생김 | 예 | 표본 수 확대, ε 조정, 기대 정확도 조정 |
| 측정의 벽 | 정확도 검증도 민감 데이터 접근이 될 수 있음 | 아니오 | 평가 데이터·메트릭·검증 예산 설계 |
이 구분이 중요합니다.
코시 분포의 평균을 못 맞힌다면 차등 프라이버시 문제가 아닙니다. 평균이라는 목표가 애초에 불안정합니다.
0부터 1까지의 평균에서 사람 수와 ε이 정해져 있는데 오차를 더 줄일 수 없다면, 그것은 정보의 벽입니다. 받아들여야 하는 비용입니다.
결과가 좋아 보이는지 나빠 보이는지 판단이 흔들린다면, 측정의 벽일 가능성이 큽니다. 메트릭과 검증 설계를 다시 봐야 합니다.
결론: 어느 벽인지부터 물어야 합니다
‘차등 프라이버시는 정확도가 떨어진다.’
이 말은 너무 큽니다. 좋은 질문은 따로 있습니다.
지금 부딪힌 것이 통계의 벽인가, 정보의 벽인가, 측정의 벽인가?
통계의 벽이면 추정 대상을 바꿔야 합니다.
정보의 벽이면 예산과 표본 수, 기대 정확도를 조정해야 합니다.
측정의 벽이면 검증 데이터와 메트릭을 다시 설계해야 합니다.
세 벽을 구분하지 못하면 차등 프라이버시를 억울하게 욕하게 됩니다. 반대로 이 구분 없이 ‘노이즈만 잘 넣으면 된다’고 믿으면, 증명된 하한과 검증 비용을 놓치게 됩니다.
차등 프라이버시를 제대로 이해했다는 신호는 노이즈 공식을 외우는 것이 아닙니다. 어느 한계가 DP의 책임이고, 어느 한계가 통계와 측정의 책임인지 가를 수 있는 것입니다.
참고 문헌
Footnotes
-
Near, J., Darais, D., et al. — Guidelines for Evaluating Differential Privacy Guarantees (NIST SP 800-226), NIST, 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2 ↩3
-
NIST/SEMATECH e-Handbook of Statistical Methods — Cauchy Distribution. https://www.itl.nist.gov/div898/handbook/eda/section3/eda3663.htm ↩
-
Kamath, G., Singhal, V., Ullman, J. — Private Mean Estimation of Heavy-Tailed Distributions, COLT, 2020. https://proceedings.mlr.press/v125/kamath20a.html ↩
-
Dwork, C., Roth, A. — The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩ ↩2
-
Hardt, M., Talwar, K. — On the Geometry of Differential Privacy, STOC, 2010. https://arxiv.org/abs/0907.3754 ↩
-
Bun, M., Ullman, J., Vadhan, S. — Fingerprinting Codes and the Price of Approximate Differential Privacy, STOC, 2014. https://arxiv.org/abs/1311.3158 ↩
-
Dwork, C., Feldman, V., Hardt, M., Pitassi, T., Reingold, O., Roth, A. — Preserving Statistical Validity in Adaptive Data Analysis, STOC/Science, 2015. https://arxiv.org/abs/1411.2664 ↩