TopDown 알고리즘 논쟁의 진짜 범인은 노이즈가 아니라 사후 보정입니다
2020 미국 인구총조사의 TopDown 알고리즘이 통계학자들에게 비판받은 이유를, 노이즈가 아닌 사후 보정 단계의 편향과 선거구 논쟁을 중심으로 짚습니다.
정현진(Hyunjin Jeong) · 2026-06-16 · 9분 분량

한 주(州) 인구통계학자가 인구총조사 표를 열어 보니, 인구가 적은 한 카운티에서는 5세 미만 아동 수가 실제보다 평균 1.53명씩 적게 잡혀 있었습니다.
같은 표에서 15~19세 인구는 거꾸로 평균 3.6명씩 많게 잡혀 있었습니다.1
오차의 크기보다 방향이 더 이상했습니다. 작은 칸은 위로, 큰 칸은 아래로, 마치 누가 의도한 듯 한쪽으로 쏠려 있었기 때문입니다.
한 줄 요약 2020 미국 인구총조사의 TopDown 알고리즘에서 비판의 핵심은 평균 0인 노이즈가 아니라, 음수와 제약을 메우려는 사후 보정 단계입니다. 이 보정이 작은 수는 위로, 큰 수는 아래로 미는 체계적 편향을 만들어 작은 지역과 소수 인구 분석을 흔듭니다.
인구조사에 노이즈를 넣기로 한 이유는 재구성 공격이었습니다
미국 인구조사국(Census Bureau)은 2010년에 이미 공표했던 인구총조사 표를 가지고 한 가지 실험을 했습니다.
당시 표는 전통적 비식별화 기법인 데이터 스와핑(data swapping)을 거친 상태였습니다. 즉 일부 가구의 위치를 서로 바꿔 신원을 가린 데이터였습니다.
그런데 공표된 표만 가지고 3억 명이 넘는 개인 레코드를 거꾸로 복원해 냈습니다.2 이것이 재구성 공격(database reconstruction)입니다. 공개된 집계표 여러 장을 연립방정식처럼 풀면 원본 개인 기록이 다시 떠오른다는 뜻입니다.
복원 결과를 상용 데이터와 맞춰 보니 전체 일치율은 91.8%였고, 사람이 1~9명뿐인 가장 작은 블록에서는 74.0%까지 떨어졌습니다.2 작은 지역일수록 한 사람의 특징이 그대로 노출된다는 신호입니다.
인구조사국은 데이터 스와핑이 이런 공격을 막도록 설계된 적이 없으며, 막을 만큼 노이즈를 넣으면 데이터를 쓸 수 없을 만큼 부정확해진다고 판단했습니다.3 그래서 트레이드오프를 수치로 다룰 수 있는 형식적 프라이버시, 곧 차등 프라이버시(DP)로 갈아탑니다.
여기서부터 모든 논쟁이 ‘프라이버시냐 정확도냐’의 줄다리기가 됩니다.
TopDown은 노이즈를 국가에서 블록까지 쪼개 내려보냅니다
새 시스템의 이름이 TopDown 알고리즘(TopDown Algorithm, TDA)입니다. 1990년부터 2010년까지 쓰던 레코드 스와핑 방식을 대체합니다.4
동작은 두 단계로 나뉩니다.
먼저 원자료에 대한 핵심 질의에 노이즈를 더해 ‘노이즈가 섞인 측정값(noisy measurements)’을 만듭니다. 이때 프라이버시 회계 방식으로 zCDP(zero-Concentrated Differential Privacy)를 쓰고, 더하는 노이즈는 평균 0을 중심으로 한 이산 가우시안 분포에서 뽑습니다.4
다음으로 이 측정값을 모아, 사람과 주택을 한 줄에 하나씩 담은 마이크로데이터로 다시 짜 맞춥니다.4
핵심은 이 짜 맞추는 순서가 위에서 아래라는 점입니다. 미국 전체 → 주 → 카운티 → 트랙 → 블록 그룹 → 블록 순으로 내려갑니다.5
상위에서 정한 값을 고정한 채, 하위 지역들의 값을 각자의 노이즈 값에 최대한 가깝게 두되 합이 부모 지역 총계와 정확히 맞도록 고릅니다.5
핸드북의 설명이 직관적입니다. 한 카운티 안 모든 트랙의 노이즈 인구를 본 뒤, 각 트랙 값을 자기 노이즈에 최대한 가깝게 두되 그 합이 카운티 총인구와 맞도록 정한다는 것입니다.5
이렇게 하면 블록 표를 모으면 블록 그룹 표가 되고, 그것을 모으면 트랙 표가 되는 식으로 계층 간 숫자가 어긋나지 않습니다.6
위에서 아래로 가는 이유는 정확도 때문입니다. 블록을 따로따로 추정해 위로 더하는 것보다, 인구조사 지리의 나무 구조를 통째로 활용하는 편이 더 정밀합니다.7
진짜 문제는 노이즈가 아니라 그다음 보정 단계입니다
여기서 논쟁의 무게중심이 옮겨 갑니다.
노이즈 자체는 편향을 만들지 않습니다. 양수와 음수가 같은 확률로 나오는 0 중심 대칭 분포에서 뽑히기 때문에, 평균을 내면 0으로 수렴합니다.8
문제는 그다음입니다. 작은 칸에서는 음의 노이즈가 인구를 음수로 만들 수 있습니다. 인구 1명에 −2가 더해지면 −1명이 됩니다.9
인구가 음수일 수는 없으니, 음수를 없애고 정수로 맞추는 보정이 필요합니다. 이 단계가 사후 보정(post-processing)입니다. 이미 나온 노이즈 측정값을 손봐 값을 음수가 아니게, 정수로, 계층 합이 맞게 다듬는 작업입니다.9
인구조사국은 이 지점을 두고 ‘DAS는 교과서적 차등 프라이버시에서 한 가지 중요한 방식으로 벗어난다’고 직접 적었습니다.10 모든 인구·주택 수는 정수여야 하고 음수일 수 없으며, 특정 불변량(invariant)은 노이즈 없이 그대로 둔다는 제약이 추가되기 때문입니다.10
여기서 함정이 생깁니다. 사후 보정은 깔끔한 ε 보장의 바깥에서 일어나는 계산입니다.
인구조사국 설계자들 스스로도 음수를 허용하지 않는 제약이 ‘정확도의 범인’이며, 이 제약이 만든 오차는 프라이버시 예산(ε)으로 합리적으로 통제할 수 없다고 인정했습니다.11
즉 음수를 0으로 밀어 올리는 그 한 동작이, 노이즈와 무관한 새 오차를 데이터에 심습니다.
한 블록을 따라가면 편향의 방향이 보입니다
숫자로 보면 더 선명합니다.
인구조사국 공식 예시에서, 한 블록 그룹 안 블록별 노이즈 인구의 예비 합계가 257이 나왔습니다. 그런데 프라이버시 보호된 블록 그룹 총합은 254였습니다.12
그러면 257을 254로 끌어내려야 합니다. 부모 지역과의 일관성 제약 때문에, 3명만큼을 어딘가에서 깎아 블록에 다시 나눠야 합니다.12
이 재배분이 한 방향으로 쏠립니다. 음수가 될 뻔한 작은 칸은 0이나 그 위로 떠받쳐지고, 큰 칸은 총합을 맞추느라 깎입니다.
그 결과 작은 값은 약간의 양의 편향을, 큰 값은 음의 편향을 갖게 됩니다. 작은 칸은 공표값이 실제보다 같거나 큰 쪽으로, 큰 칸은 같거나 작은 쪽으로 기웁니다.13
인구조사국의 공식 메트릭 문서도 같은 구조를 말합니다. 인구가 적은 지역은 공표값(MDF)이 원자료(CEF)보다 체계적으로 큰 양의 편향을, 인구가 많은 지역은 음의 편향을 갖는 경향이 있습니다.14
규모별로 갈리는 편향을 표로 보면 이렇습니다. 인구 5,000~9,999명의 소규모 카운티에서 가구 규모별 평균오차입니다.13
| 가구 규모 | 평균오차(가구 수) | 편향 방향 |
|---|---|---|
| 1인 가구 | −10.52 | 음(아래로) |
| 2인 가구 | −17.54 | 음(아래로) |
| 3인 가구 | −8.43 | 음(아래로) |
| 5인 가구 | +9.82 | 양(위로) |
| 6인 가구 | +12.60 | 양(위로) |
| 7인 가구 | +12.86 | 양(위로) |
노이즈는 평균 0인데도 결과에 0이 아닌 편향이 남는 이유가 바로 이 보정에 있습니다. 한 카운티 안에서도 칸 크기에 따라 부호가 갈립니다.
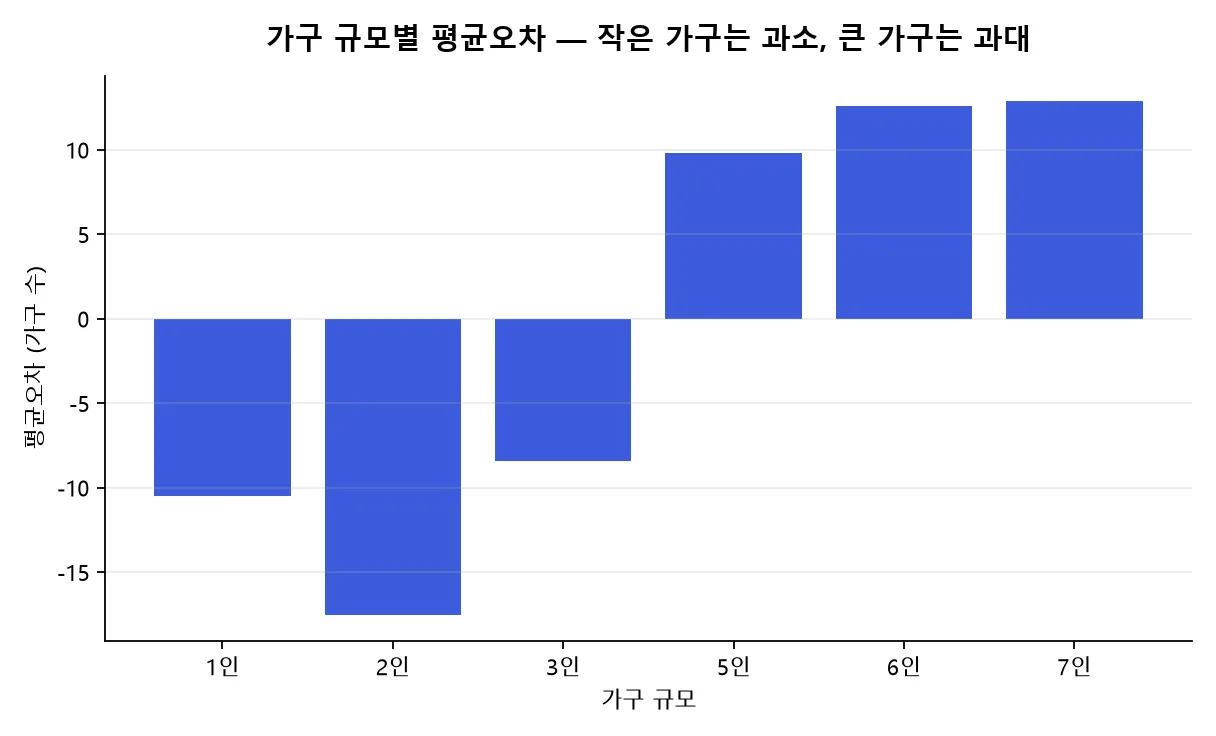
인구 5,000~9,999명 소규모 카운티의 가구 규모별 평균오차
이 편향은 작은 지역·소수 인구 연구를 정면으로 때립니다
추상적인 편향이 실제 연구에서는 통계 값을 절반으로, 두 배로 흔듭니다.
한 연구팀은 이 데이터로 사망률을 다시 계산해 보았습니다. 일부 경우 2010년 원본 인구로 계산한 사망률이 DP 보호 인구로 계산한 값의 두 배까지 차이 났습니다.15 분모인 인구가 흔들리면 비율 지표가 통째로 흔들린다는 뜻입니다.
오차는 균일하지도 않았습니다. 인구가 적은 지역일수록, 그리고 비히스패닉 흑인과 히스패닉 인구에서 변화가 더 크게 나타났습니다.16 건강 격차 연구가 의지하는 바로 그 소수 집단에 왜곡이 가장 세게 내려앉습니다.
도농 격차도 같은 방향이었습니다. 도시화 수준이 낮거나 대도시에 인접하지 않은 지역일수록 사망률 추정 변화가 컸습니다.17
후속 연구는 카운티 단위에서 이 패턴을 확인했습니다. 도시에서 농촌으로 갈수록 추정 정확도가 꾸준히 떨어졌는데, 유일한 예외가 비히스패닉 백인 인구였습니다.18 결과적으로 백인 인구가 가장 정확한 인구수를 받는 구조가 됩니다.
데이터 사용자 쪽 입장도 분명합니다. IPUMS는 인구총조사 데이터의 강점이 표본조사로는 닿지 못하는 작은 지역의 전국 단위 고품질 수치라는 점을 짚으며, 새 시스템이 선거구 획정과 여러 연구에 부정적 영향을 준다고 결론지었습니다.19
선거구 획정에서 가장 큰 논쟁이 터졌습니다
가장 격렬한 비판은 하버드 Imai 연구팀에게서 나왔습니다.
이들은 DAS가 주입한 노이즈 때문에, 현재 해석되고 운영되는 방식으로는 헌법상 ‘1인 1표(One Person, One Vote)’ 원칙을 정확히 지키기 어렵다고 결론지었습니다.20
핵심 주장은 편향이 무작위가 아니라는 데 있습니다. DAS가 인구를 지역 간에 옮기는 방향이 인종·정파 구성과 상관되어, 인종·정파 이질성을 인위적으로 줄인다는 것입니다.21
구체적으로는 백인과 비백인이 섞인 혼합 정밀구역(precinct)이 동질적인 구역보다 인구를 더 많이 잃었습니다. 이렇게 되면 실제보다 거주지 분리가 심해 보이고, 다수-소수 선거구(majority-minority district) 시뮬레이션에서 원래 2개여야 할 구역이 1개로 줄어드는 경우도 나왔습니다.22
규모도 짚었습니다. 분석에 쓴 2021년 4월 시연 데이터에서, 프라이버시 예산이 큰 DAS-12.2 설정조차 정밀구역 인구가 원본 대비 약 1.0% 달랐습니다.23 정밀구역 규모에서 1%는 선거구 결과를 뒤집기에 충분한 크기입니다.
한 가지 역설도 함께 보고했습니다. 노이즈에도 불구하고 유권자 명부를 이용한 개인 인종 예측 정확도는 원본 2010년 데이터와 비슷했습니다.24 비판자들이 정작 신경 쓰는 수준에서는 기대한 프라이버시 이득은 주지 못한 채, 선거구 분석 효용만 떨어뜨렸다는 지적입니다.
인구조사국의 반론은 ‘집계하면 상쇄된다’입니다
인구조사국의 반박은 ‘어느 집계 수준에서 보느냐’에 걸려 있습니다.
먼저 사실관계를 짚어야 합니다. 흔한 오해와 달리, 블록 단위 총인구는 불변량이 아닙니다. 노이즈 없이 그대로 보존하는 값은 일부러 몇 개로만 추렸습니다. 각 주와 DC·푸에르토리코의 총인구, 각 블록의 주택 호수, 각 블록의 점유된 집단 거주시설 수와 종류뿐입니다.25
다시 강조하면, 블록의 주택 ‘호수’는 불변량이지만 그 안에 사는 ‘사람 수’는 불변량이 아닙니다.25
그래서 반론은 블록 인구 불변량에 기대지 않습니다. 두 기둥으로 섭니다.
첫째, 노이즈 측정값 자체는 무편향입니다. 이산 가우시안 메커니즘에서 노이즈 측정값의 기대 오차는 0이므로, 체계적 편향은 프라이버시 메커니즘이 아니라 그 뒤의 음수 제거와 사후 보정 탓이라는 것입니다.26
둘째, 선거구는 블록을 모아 만든 단위이므로 블록 단위 오차가 집계 과정에서 상쇄됩니다. 인구조사국은 선거구가 알고리즘 실행 시점에는 정의되지도 않는다는 점을 들어, 가장 낮은 지리 수준(블록 그룹·블록)에 프라이버시 예산을 가장 많이 배정해 정확도를 끌어올렸다고 설명합니다.27
인구조사국의 후속 논의는 한 발 더 나갑니다. 무편향 노이즈 측정값을 선거구 규모로 모으면, 음수 항이 많더라도 합리적인 선거구를 만들 수 있고, 그 집계의 분산은 구성 통계들의 분산을 더해 정확히 계산할 수 있다는 설명입니다.28
측정해 둔 질의가 사용자가 실제로 원하는 집계와 맞으면, 2020년 선거구 데이터의 어떤 집계든 그 불확실성을 독립 통계들의 분산 합으로 곧바로 구할 수 있다는 주장도 같은 맥락입니다.29 통제 불가능한 사후 보정 오차 대신, 계산 가능한 불확실성을 사용자에게 주겠다는 뜻입니다.
결국 양측은 같은 데이터를 두고 다른 지점을 봅니다. 비판자는 보정이 끝난 공표 데이터를 작은 지역에서 보고, 인구조사국은 보정 이전의 무편향 측정값을 선거구 규모로 모아서 봅니다.
무엇이 결판났고 무엇은 아직 아닌지 분명히 해야 합니다
이 논쟁은 ‘DP가 틀렸다’는 이야기가 아닙니다.
설계자 본인이 정확도 손상의 위치를 차등 프라이버시 노이즈가 아니라 음수를 없애는 사후 보정 제약으로 콕 집었습니다.30 0인 값을 0이 아닌 값으로 바꾸면서 음수를 허용하지 않는 시스템이라면, 과거의 억제나 스와핑을 포함해 무엇이든 같은 체계적 편향을 겪습니다.30
경계는 여기 있습니다. 논쟁의 대상은 형식적 프라이버시 틀 자체가 아니라, 특정 사후 보정과 공표 제품 설계의 선택입니다. 인구조사국 설계자들의 후속 논문 제목이 그 경계를 그대로 말합니다. 노이즈 측정값도 중요하지만, 공표되는 인구총조사 제품의 설계가 정확도에 훨씬 더 중요하다는 것입니다.31
아직 결판나지 않은 전제도 따로 있습니다. 스와핑을 버리게 만든 재구성 위협이 정말 심각했는가 하는 물음입니다.
반박 연구에 따르면, 무작위로 뽑은 사람이 무작위로 고른 블록의 누군가와 나이·성별이 정확히 일치할 확률이 52.6%였습니다.32 인구조사국이 ‘성공’이라 부른 복원 일치의 상당수가 정보 유출이 아니라 우연으로 설명된다는 것입니다.
같은 분석은 복원 일치의 대다수(68.6%)가 나이·성별을 무작위로 배정해도 나타날 수준이라고 봅니다.33 복원 데이터에 독립적인 식별 정보가 없어 정식 노출 연구의 확인 기준도 충족하지 못한다는 지적입니다.
이 두 갈래는 서로 다른 질문입니다. 사후 보정 편향이 작은 지역을 흔든다는 사실과, 애초의 재구성 위협이 얼마나 컸는가 하는 문제는 분리해서 봐야 합니다.
확실해진 것은 하나입니다. 제약 있는 사후 보정이 프라이버시 예산으로 다스려지지 않는 오차를 데이터에 심는다는 점입니다.34 그 오차가 가장 크게 닿는 곳이 작은 지역과 소수 인구이고, 바로 그래서 통계학자들이 목소리를 높였습니다.
참고 문헌
Footnotes
-
U.S. Census Bureau, ‘Disclosure Avoidance for the Demographic and Housing Characteristics File,’ Census Brief C2020BR-08, 2023 — State Demographer use case(Table 4). https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-08.pdf ↩
-
U.S. Census Bureau, ‘Why the Census Bureau Chose Differential Privacy,’ Census Brief C2020BR-03, March 2023, pp.3–4. https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-03.pdf ↩ ↩2
-
U.S. Census Bureau, Census Brief C2020BR-03, March 2023, p.4. https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-03.pdf ↩
-
John M. Abowd et al., ‘The 2020 Census Disclosure Avoidance System TopDown Algorithm,’ arXiv:2204.08986, 2022(abstract·§3). https://arxiv.org/abs/2204.08986 ↩ ↩2 ↩3
-
U.S. Census Bureau, ‘Disclosure Avoidance for the 2020 Census: An Introduction’(Handbook), 2021, p.17. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩ ↩2 ↩3
-
U.S. Census Bureau, Handbook 2021, pp.16–17. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩
-
Abowd et al. 2022, arXiv:2204.08986(motivation for TDA). https://arxiv.org/abs/2204.08986 ↩
-
U.S. Census Bureau, Handbook 2021, ‘Multipass Optimization’ 절. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩
-
U.S. Census Bureau, Handbook 2021, ‘Post-Processing the Noisy Statistics to Produce Tables’ 절. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩ ↩2
-
U.S. Census Bureau, Handbook 2021, ‘Invariants’ / ‘Additional Constraints’ 절. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩ ↩2
-
John M. Abowd & Michael B. Hawes, ‘Noisy Measurements Are Important, the Design of Census Products Is Much More Important,’ arXiv:2312.14191, 2023(§3). https://arxiv.org/abs/2312.14191 ↩
-
U.S. Census Bureau, Handbook 2021, ‘Example of Post-Processing’ 절. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩ ↩2
-
U.S. Census Bureau, Census Brief C2020BR-08, 2023, ‘Noise and Bias’ 절·DHC Use Case(Table 9). https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-08.pdf ↩ ↩2
-
U.S. Census Bureau, ‘Revised Data Metrics for 2020 Disclosure Avoidance’(DAS metrics overview), 2021-06-08. https://www2.census.gov/programs-surveys/decennial/2020/program-management/data-product-planning/2010-demonstration-data-products/01-Redistricting_File--PL_94-171/2021-06-08_ppmf_Production_Settings/2021-06-08-das-metrics-overview.pdf ↩
-
Alexis R. Santos-Lozada, Jeffrey T. Howard & Ashton M. Verdery, ‘How differential privacy will affect our understanding of health disparities in the United States,’ PNAS 117(24):13405–13412, 2020, doi:10.1073/pnas.2003714117(open-access PMC7306796). https://pmc.ncbi.nlm.nih.gov/articles/PMC7306796/ ↩
-
Santos-Lozada, Howard & Verdery 2020, PNAS 117(24), doi:10.1073/pnas.2003714117. https://pmc.ncbi.nlm.nih.gov/articles/PMC7306796/ ↩
-
Santos-Lozada, Howard & Verdery 2020, PNAS 117(24), doi:10.1073/pnas.2003714117. https://pmc.ncbi.nlm.nih.gov/articles/PMC7306796/ ↩
-
Mueller & Santos-Lozada 2022, ‘The 2020 US Census Differential Privacy Method Introduces Disproportionate Discrepancies for Rural and Non-White Populations,’ Population Research and Policy Review(open-access PMC11105149). https://pmc.ncbi.nlm.nih.gov/articles/PMC11105149/ ↩
-
IPUMS / Minnesota Population Center, ‘Changes to Census Bureau Data Products.’ https://www.ipums.org/changes-to-census-bureau-data-products ↩
-
Christopher T. Kenny, Shiro Kuriwaki, Cory McCartan, Evan T. R. Rosenman, Tyler Simko & Kosuke Imai, ‘The use of differential privacy for census data and its impact on redistricting,’ arXiv:2105.14197, 2021(preprint of Science Advances 7(41), doi:10.1126/sciadv.abk3283). https://arxiv.org/abs/2105.14197 ↩
-
Kenny et al. 2021, arXiv:2105.14197(Science Advances 7(41), doi:10.1126/sciadv.abk3283). https://arxiv.org/abs/2105.14197 ↩
-
Kenny et al. 2021, arXiv:2105.14197(Science Advances 7(41), doi:10.1126/sciadv.abk3283). https://arxiv.org/abs/2105.14197 ↩
-
Kenny et al. 2021, arXiv:2105.14197(Science Advances 7(41), doi:10.1126/sciadv.abk3283). https://arxiv.org/abs/2105.14197 ↩
-
Kenny et al. 2021, arXiv:2105.14197(Science Advances 7(41), doi:10.1126/sciadv.abk3283). https://arxiv.org/abs/2105.14197 ↩
-
Abowd et al. 2022, arXiv:2204.08986 §5.2(Invariants). https://arxiv.org/abs/2204.08986 ↩ ↩2
-
Abowd et al. 2022, arXiv:2204.08986 §3(Policy and Practical Constraints). https://arxiv.org/abs/2204.08986 ↩
-
Abowd et al. 2022, arXiv:2204.08986 §6.3(Problem Statement and Utility Criteria). https://arxiv.org/abs/2204.08986 ↩
-
Abowd & Hawes, arXiv:2312.14191, §4. https://arxiv.org/abs/2312.14191 ↩
-
Abowd & Hawes, arXiv:2312.14191, §2. https://arxiv.org/abs/2312.14191 ↩
-
Abowd et al. 2022, arXiv:2204.08986 §3(Policy and Practical Constraints). https://arxiv.org/abs/2204.08986 ↩ ↩2
-
Abowd & Hawes, arXiv:2312.14191(Abstract / Introduction). https://arxiv.org/abs/2312.14191 ↩
-
Steven Ruggles 2025, ‘When Privacy Protection Goes Wrong’(summarizing Ruggles & Van Riper 2022, Population Research and Policy Review 41), PMC11913010. https://pmc.ncbi.nlm.nih.gov/articles/PMC11913010/ ↩
-
Ruggles 2025(summarizing Ruggles & Van Riper 2022, PRPR 41), PMC11913010. https://pmc.ncbi.nlm.nih.gov/articles/PMC11913010/ ↩
-
Abowd & Hawes, arXiv:2312.14191, §3. https://arxiv.org/abs/2312.14191 ↩