DP 노이즈 메커니즘은 출력 타입과 민감도로 갈린다
같은 ε이라도 합·평균엔 Laplace나 Gaussian, 범주·최빈값엔 Exponential을 써야 하는 이유와 잘못 고르면 무너지는 지점을 쿼리별로 정리합니다.
정현진(Hyunjin Jeong) · 2026-06-17 · 7분 분량
매출 집계에 차등 프라이버시를 붙이려는 엔지니어가 라이브러리 문서를 엽니다.
ε은 0.5로 정했고 예산도 계산했습니다. 그런데 막상 함수를 고르려니 make_laplace, make_gaussian, 그리고 범주를 고르는 별도 함수까지 세 갈래로 갈립니다.
‘ε만 같으면 아무거나 써도 되는 거 아닌가요?’
같은 ε을 써도 어떤 메커니즘을 고르느냐에 따라 보장이 유지되기도 하고, 출력이 통째로 무의미해지기도 합니다. 갈림길은 ε이 아니라 두 가지 질문에 있습니다. 출력이 숫자인가 아니면 항목 하나를 고르는가, 그리고 민감도를 L1으로 재는가 L2로 재는가입니다.
한 줄 요약 DP 노이즈 메커니즘은 ε이 아니라 출력 타입과 민감도 척도로 갈립니다. 수치형 합·평균은 L1 민감도를 쓰는 Laplace 또는 L2 민감도를 쓰는 Gaussian으로, 범주·최빈값처럼 항목을 고르는 출력은 점수에 비례해 확률적으로 뽑는 Exponential로 처리해야 합니다. Gaussian은 순수 ε-DP를 포기하고 δ>0를 내주는 대신 고차원·반복 쿼리에서 노이즈를 덜 누적합니다.
ε이 같아도 메커니즘이 갈리는 진짜 이유
Laplace와 Gaussian은 둘 다 쿼리 결과에 노이즈를 더하고, 그 노이즈 크기를 쿼리의 민감도에 맞춰 키웁니다. 민감도는 입력에서 한 사람의 데이터가 바뀔 때 결과가 최대 얼마나 흔들릴 수 있는지를 재는 값입니다.1
그런데 두 메커니즘은 정확히 두 가지에서 갈립니다. 제공하는 보장의 종류, 그리고 요구하는 민감도의 척도입니다.2 이 두 축이 곧 메커니즘 선택의 좌표입니다.
여기에 한 축이 더 붙습니다. 출력이 숫자가 아니라 ‘여러 후보 중 하나를 고르는 것’일 때입니다. 이 경우 노이즈를 더한다는 발상 자체가 성립하지 않아서, 더하기 노이즈 메커니즘과는 전혀 다른 도구가 필요합니다.
즉 메커니즘 선택은 ε을 정한 뒤에 따라오는 질문이 아니라, ε과 독립적으로 ‘출력 타입 × 민감도 척도’에서 먼저 결정되는 문제입니다.
민감도가 L1이냐 L2냐에서 Laplace와 Gaussian이 갈린다
같은 수치 쿼리인데도 Laplace와 Gaussian으로 나뉘는 이유는 민감도를 재는 자가 다르기 때문입니다.
Laplace 메커니즘은 L1 민감도를 쓰고 순수한 (ε,0)-DP를 보장합니다. Gaussian 메커니즘은 L2 민감도를 쓰고 (ε,δ) 계열의 보장을 제공합니다. L1 민감도는 맨해튼 거리로, L2 민감도는 유클리드 거리로 잽니다.3
이 말은 이런 뜻입니다. 결과가 여러 좌표로 이루어진 벡터라고 할 때, 한 사람이 바뀌어 각 좌표가 흔들린 양을 그냥 다 더한 것이 L1이고, 제곱해서 더한 뒤 제곱근을 취한 것이 L2입니다. 한 사람이 한 좌표만 1만큼 바꾸는 단순한 합 쿼리에서는 둘 다 1로 같습니다.
차이는 고차원에서 벌어집니다. 결과가 1000개 좌표짜리 벡터이고 한 사람이 모든 좌표를 조금씩 흔든다면, 그 변동을 단순히 더한 L1은 빠르게 커지지만 제곱·합·제곱근을 거친 L2는 훨씬 천천히 자랍니다.
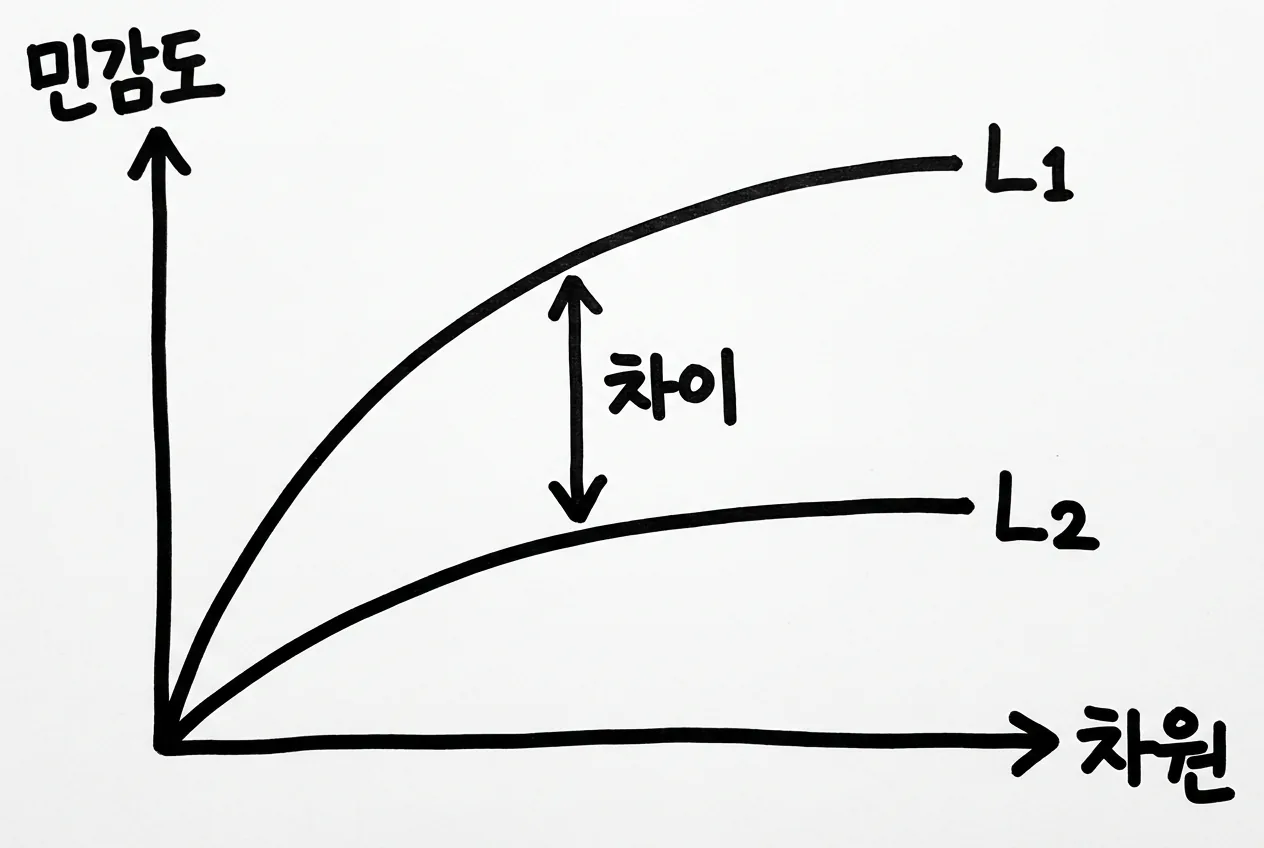
NIST의 정부 표준 문서는 이 지점을 실무 언어로 못박습니다. 고차원 출력에서는 L2 민감도가 보통 L1 민감도보다 훨씬 작고, 그래서 L2에 기대는 Gaussian이 정확도를 크게 끌어올린다는 것입니다.4
구현도 이 구분을 그대로 강제합니다. OpenDP의 측정 API에서 make_laplace는 벡터 입력을 L1 거리(l1_distance)에, make_gaussian은 L2 거리(l2_distance)에 묶습니다. 스칼라 입력에서는 둘 다 절댓값 거리를 씁니다.5
| 구분 | Laplace | Gaussian |
|---|---|---|
| 민감도 척도 | L1(맨해튼 거리) | L2(유클리드 거리) |
| 프라이버시 보장 | (ε,0)-DP, 순수 DP | (ε,δ)-DP, δ>0 필요 |
| 유리한 출력 | 저차원(k가 작음, k=1 포함) | 고차원(k가 큼) |
| OpenDP 입력 metric | absolute_distance / l1_distance |
absolute_distance / l2_distance |
저차원 출력에서는 보통 Laplace가, 고차원 출력에서는 보통 Gaussian이 더 나은 정확도를 줍니다.4
범주·최빈값에는 왜 Exponential이어야 하나
출력이 ‘가장 인기 있는 상품 카테고리’처럼 숫자가 아니라 항목 하나라면 이야기가 달라집니다.
카테고리 인덱스에 Laplace 노이즈를 더한다고 생각해 보면 문제가 바로 보입니다. ‘가전’이 3번이고 ‘식품’이 4번일 때, 3번에 노이즈를 더해 3.7이 나오면 그건 어떤 카테고리도 아닙니다. 더하기 노이즈는 값에 거리 개념이 있을 때만 의미가 있는데, 범주에는 그 거리가 없습니다.
Exponential 메커니즘은 바로 이 상황을 위해 설계됐습니다. 최선의 응답을 고르고 싶지만 계산된 값에 직접 노이즈를 더하면 그 값이 통째로 망가지는 경우, 즉 출력이 수치가 아니거나 임의의 비수치 범위인 경우를 위한 도구입니다.6
작동 방식은 ‘점수 함수 + 확률적 선택’입니다. 각 후보에 점수(유틸리티)를 매긴 뒤, 점수가 높은 후보일수록 더 높은 확률로 뽑되 항상 그 후보만 나오지는 않게 합니다. 정확히는 각 후보를 그 점수에 지수적으로 비례하는 확률로 출력하며, 이 메커니즘은 (ε,0)-DP를 보존합니다.7
핵심은 민감도를 재는 자리입니다. 점수 함수의 민감도는 데이터 인자에 대해서만 따집니다. 한 사람이 바뀔 때 점수가 최대 얼마나 변하는가가 보장의 척도이고, 후보 항목 자체에 대해서는 점수가 아무리 민감해도 괜찮습니다.8
이 덕분에 ‘가장 점수가 높은 항목 고르기’가 비수치 출력이면서도 차등 프라이버시 보장을 유지할 수 있습니다. 구현에서도 이 선택 문제는 별도 메커니즘으로 분리돼 있어서, OpenDP의 make_report_noisy_max_gumbel은 점수 벡터를 받아 가장 높은 점수의 인덱스를 사적으로 골라 인덱스 값을 출력합니다.9
같은 상황, 세 메커니즘을 숫자로 비교한다
구체적인 두 쿼리로 메커니즘이 어떻게 달라지는지 보겠습니다.
먼저 ‘도시별 매출 합’ 쿼리입니다. 한 사람이 결과를 최대 1만큼 바꾼다고 보면 민감도는 1이고, ε=1을 쓴다고 합시다. Laplace 메커니즘은 결과에 Lap(민감도/ε)에서 뽑은 노이즈를 더합니다.10 여기서는 민감도 1을 ε 1로 나눈 값, 즉 척도 1짜리 Laplace 노이즈가 붙습니다. 이 노이즈의 분산은 척도의 제곱의 두 배이므로 2입니다. 데이터 규모가 100만 건이든 1000만 건이든 이 오차 크기는 그대로입니다.
이미지 출처: Unknown author · CC BY-SA 3.0 — Wikimedia Commons
{kind=link}
다음은 ‘가장 인기 있는 상품 카테고리’ 쿼리입니다. 여기에 같은 Laplace를 억지로 끼우면, 카테고리 인덱스라는 숫자에 노이즈가 더해져 존재하지 않는 인덱스가 나옵니다. 보장이 깨지기 전에 출력의 의미가 먼저 깨집니다. 이 쿼리는 Exponential 메커니즘으로 각 카테고리의 점수에 비례해 하나를 뽑아야 합니다.
구현 라이브러리는 이 구분을 metric 차원에서 강제합니다. OpenDP make_laplace는 L1 계열 입력만 받고 출력 측도로 MaxDivergence만 허용하며, make_gaussian은 L2 계열 입력에 ZeroConcentratedDivergence만 허용합니다. 잘못된 metric을 끼우면 측정 자체가 성립하지 않습니다.11
프로덕션 쪽도 마찬가지입니다. Google의 DP 라이브러리는 인원 집계, 합, 평균, 분산, 분위수 같은 수치 집계를 Laplace와 Gaussian으로 구현하고, 두 메커니즘 모두 안전한 노이즈 생성을 씁니다.12 수치 집계는 더하기 노이즈에, 범주 선택은 별도 선택 메커니즘에 붙는다는 경계가 코드에도 그대로 새겨져 있는 셈입니다.
Gaussian은 δ>0를 내주고 합성에서 돌려받는다
Gaussian이 순수 (ε,0)-DP가 아니라 (ε,δ)-DP를 요구한다는 건 공짜가 아닙니다. δ는 보장이 깨질 수 있는 작은 확률을 허용한다는 뜻이라, δ>0를 내주는 것은 약한 보장을 받아들이는 거래입니다.
대신 Gaussian은 고차원·반복 쿼리에서 돌려받습니다. 앞서 본 대로 고차원에서는 L2 민감도가 L1보다 훨씬 작고, 여러 쿼리를 합성할 때 L2 기반 회계가 오차를 덜 누적합니다.
이 ‘덜 누적된다’를 정량화하는 틀이 Rényi 차등 프라이버시입니다. 이것은 Rényi 발산에 기반한 차등 프라이버시의 완화 정의로, 표준 DP의 핵심 성질을 공유하면서도 서로 다른 메커니즘을 여러 번 합성할 때 그 비용을 더 타이트하게 분석하게 해줍니다.13 즉 같은 ε 예산으로 더 많은 쿼리를 돌릴 여지가 생깁니다.
보정을 더 조이는 방향도 있습니다. 고전 Gaussian의 분산 공식은 고프라이버시 영역에서 전혀 타이트하지 않고 저프라이버시 영역으로 확장되지도 않습니다. 분산을 꼬리 근사 대신 정규분포의 누적분포함수로 직접 보정하는 analytic Gaussian은, 고전 방식 대비 노이즈 분산을 최소 3분의 1 줄입니다.14
구현에서도 이 거래가 드러납니다. OpenDP make_gaussian은 L2 거리에 묶이고 기본 출력 측도가 ZeroConcentratedDivergence, 즉 δ>0 계열인 반면, make_laplace는 L1 거리에 묶이고 순수 ε에 해당하는 MaxDivergence를 씁니다.11
잘못 고르면 어디가 무너지고, 무엇은 메커니즘이 지켜주지 않는가
메커니즘을 잘못 고르면 무너지는 자리가 둘로 갈립니다.
범주형 출력에 Laplace를 쓰면 보장이 아니라 ‘의미’가 먼저 무너집니다. 존재하지 않는 인덱스가 나와 출력이 쓸모를 잃습니다. 반대로 Gaussian을 δ=0인 척 순수 ε-DP라고 보고하면 보장 자체가 거짓이 됩니다. Gaussian은 δ>0를 전제로만 (ε,δ)-DP를 보장하기 때문입니다.3
그런데 올바른 메커니즘을 골라도 끝이 아닙니다. 메커니즘 선택이 지켜주지 않는 영역이 따로 있습니다.
대표적인 것이 부동소수점 누설입니다. 교과서식 Laplace 샘플링 절차는 수학적 추상화와 달리 double precision 수 위에 구멍 뚫린 분포를 만들어, 단 몇 번의 쿼리만으로 차등 프라이버시 보장을 깨뜨릴 수 있습니다.15 올바른 Laplace를 골랐는데도 구현 디테일에서 보장이 새는 것입니다.
이건 학술적 우려가 아니라 실제 라이브러리가 인정하는 문제입니다. Google DP 라이브러리는 자사 부동소수점 구현이 반올림·반복 반올림·재정렬 공격에 취약하다고 명시하고, 이를 막기 위해 Laplace와 Gaussian 구현에 안전한 노이즈 생성을 씁니다. 정수 구현은 같은 취약점에 노출되지 않는다고 덧붙입니다.12
정부 표준도 같은 경계를 둡니다. NIST SP 800-226은 차등 프라이버시의 수학 틀이 실제 구현으로 옮겨질 때 흔히 생기는 함정을 프라이버시 위험요소로 식별합니다.16 메커니즘을 골랐다고 보장이 완성되는 게 아니라, 민감도를 잘못 잡거나 부동소수점이 새면 보장은 여전히 깨집니다.
다음 쿼리에서 바로 쓰는 결정 순서
새 쿼리 앞에서 메커니즘을 고를 때는 출력 타입부터 묻는 것이 가장 빠릅니다.
먼저 출력이 숫자인지 아니면 후보 집합에서 하나를 고르는지 봅니다. 합·평균·분위수 같은 수치 쿼리는 더하기 노이즈 메커니즘으로, 범주·최빈값처럼 항목을 고르는 쿼리는 Exponential 계열 선택 메커니즘으로 갑니다.17
수치 쿼리라면 다음으로 순수 ε-DP가 꼭 필요한지 묻습니다. 순수 ε-DP가 요구되면 Gaussian은 선택지에서 빠지고 Laplace를 씁니다. 둘 중 어느 보장이든 괜찮다면 정확도로 고릅니다. 저차원 출력에서는 보통 Laplace가, 고차원 출력에서는 L2 민감도 덕에 보통 Gaussian이 낫습니다.17
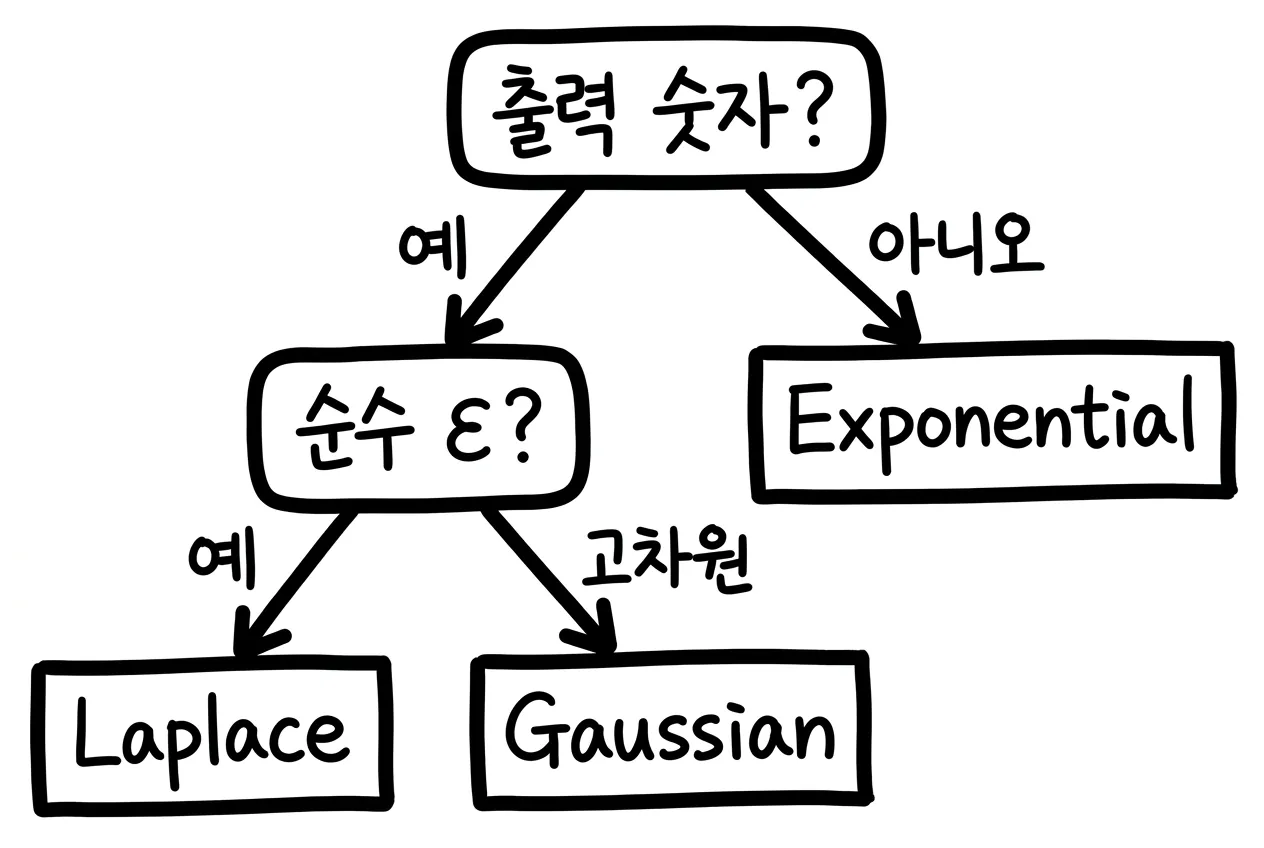
| 질문 | 답 | 메커니즘 |
|---|---|---|
| 출력이 숫자인가? | 아니다(항목 선택) | Exponential |
| 출력이 숫자인가? | 그렇다 | 다음 질문으로 |
| 순수 ε-DP가 필요한가? | 그렇다 | Laplace |
| 고차원·반복 쿼리인가? | 그렇다, δ>0 허용 | Gaussian |
| 저차원 단발 쿼리인가? | 그렇다 | Laplace |
마지막 한 가지가 남습니다. 메커니즘을 맞게 골랐어도 구현을 직접 짜면 위험이 커집니다. NIST는 메커니즘을 직접 구현하지 말고 충분히 검증된 라이브러리를 쓰라고 강하게 권고합니다. 직접 만든 구현은 프라이버시 취약점 위험을 키우기 때문입니다.18
그래서 ‘어떤 메커니즘인가’라는 질문은 결국 ‘어떤 올바른 구현인가’라는 질문과 한 묶음입니다.
참고 문헌
Footnotes
-
NIST, "Guidelines for Evaluating Differential Privacy Guarantees" (SP 800-226, March 2025), §4.1. "Both work by adding noise to the output of a query, and both mechanisms scale the noise according to the sensitivity of the underlying query." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩
-
NIST SP 800-226 (2025), §4.1, "Choosing a Mechanism". "While both the Laplace and the Gaussian mechanisms add noise to a query's output to satisfy differential privacy, they differ in two major ways: the guarantee they provide and the measure of sensitivity they require." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩
-
NIST SP 800-226 (2025), §4.1. "The L1 sensitivity is measured using L1 distance ... while the L2 sensitivity is measured using L2 distance ... The Laplace mechanism ... uses L1 sensitivity and guarantees (ε, 0)-differential privacy ... The Gaussian mechanism ... uses L2 sensitivity and guarantees ... the ε, δ variant." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩ ↩2
-
NIST SP 800-226 (2025), §4.1, "Choosing a Mechanism". "For high-dimensional outputs, L2 sensitivity is typically much smaller than L1 sensitivity, which significantly improves accuracy ... For queries with low-dimensional outputs ... the Laplace mechanism often provides better accuracy. For queries with high-dimensional outputs ... the Gaussian mechanism often provides better accuracy." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩ ↩2
-
OpenDP (Harvard), Measurements API —
make_laplace/make_gaussian. make_laplace binds vector inputs tol1_distance, make_gaussian tol2_distance; both useabsolute_distancefor scalars. https://docs.opendp.org/en/stable/api/python/opendp.measurements.html ↩ -
Cynthia Dwork, Aaron Roth, "The Algorithmic Foundations of Differential Privacy" (2014), §3.4. "The exponential mechanism was designed for situations in which we wish to choose the 'best' response but adding noise directly to the computed quantity can completely destroy its value ... the natural building block for answering queries with arbitrary utilities (and arbitrary non-numeric range)." https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
Dwork & Roth (2014), Def. 3.4 & Thm. 3.10. "The exponential mechanism M_E(x,u,R) selects and outputs an element r ∈ R with probability proportional to exp(εu(x,r)/2Δu). ... The exponential mechanism preserves (ε,0)-differential privacy." https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
Dwork & Roth (2014), §3.4. "we care only about the sensitivity of u with respect to its database argument; it can be arbitrarily sensitive in its range argument: Δu ≡ max_{r∈R} max_{x,y:‖x−y‖₁≤1} |u(x,r)−u(y,r)|." https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
OpenDP (Harvard), Measurements API —
make_report_noisy_max_gumbel. "Make a Measurement that takes a vector of scores and privately selects the index of the highest score." (output type usize) https://docs.opendp.org/en/stable/api/python/opendp.measurements.html ↩ -
Dwork & Roth (2014), Def. 3.3. "the Laplace mechanism is defined as: M_L(x,f(·),ε) = f(x) + (Y₁,...,Y_k) where Y_i are i.i.d. random variables drawn from Lap(Δf/ε)." (Laplace scale b has variance 2b².) https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
OpenDP (Harvard), Measurements API —
make_laplace/make_gaussian. "make_laplace ... Output Measure: 'MaxDivergence' is the only valid option. make_gaussian ... Output Measure: 'ZeroConcentratedDivergence' is the only valid option." https://docs.opendp.org/en/stable/api/python/opendp.measurements.html ↩ ↩2 -
Google Differential Privacy Library — README. "Count, Sum, Mean, Variance, Quantiles - all supported ... Implementations of the Laplace mechanism and the Gaussian mechanism use secure noise generation. ... Our floating-point implementations are subject to the vulnerabilities described in [Casacuberta et al.] ... Our integer implementations are not." https://github.com/google/differential-privacy ↩ ↩2
-
Ilya Mironov, "Rényi Differential Privacy" (IEEE CSF 2017), arXiv:1702.07476, abstract. "a natural relaxation of differential privacy based on the Renyi divergence ... shares many important properties with the standard definition ... while additionally allowing tighter analysis of composite heterogeneous mechanisms." https://arxiv.org/abs/1702.07476 ↩
-
Borja Balle, Yu-Xiang Wang, "Improving the Gaussian Mechanism for Differential Privacy" (ICML 2018), arXiv:1805.06530, abstract. "the variance formula for the original mechanism is far from tight in the high privacy regime (ε → 0) and it cannot be extended to the low privacy regime ... analytical calibration removes at least a third of the variance of the noise compared to the classical Gaussian mechanism." https://arxiv.org/abs/1805.06530 ↩
-
Ilya Mironov, "On Significance of the Least Significant Bits for Differential Privacy" (ACM CCS 2012), Microsoft Research publication page. "the textbook sampling procedure results in a porous distribution over double-precision numbers that allows one to breach differential privacy with just a few queries into the mechanism." https://www.microsoft.com/en-us/research/publication/on-significance-of-the-least-significant-bits-for-differential-privacy/ ↩
-
NIST SP 800-226 (2025), publication summary. "Multiple factors for consideration are identified in a differential privacy pyramid along with several privacy hazards, which are common pitfalls that arise as the mathematical framework of differential privacy is realized in practice." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩
-
NIST SP 800-226 (2025), §4.1, "Choosing a Mechanism". "If the stronger pure ε-differential privacy guarantee is required, then the Gaussian mechanism is not an option. ... For queries with low-dimensional outputs ... the Laplace mechanism often provides better accuracy. For queries with high-dimensional outputs ... the Gaussian mechanism often provides better accuracy." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩ ↩2
-
NIST SP 800-226 (2025), Privacy Hazard. "Avoid custom implementations of differentially private algorithms, and use well-tested libraries instead. ... custom implementations increase the risk of privacy vulnerabilities." https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩