크롬이 RAPPOR을 내린 진짜 이유는 로컬 DP의 한계입니다
크롬은 로컬 차등 프라이버시의 모범 사례 RAPPOR을 끝내 버리고 셔플 모델로 갈아탔습니다. 정확도와 스케일 한계, 그리고 셔플러라는 새 신뢰 가정의 손익을 정리합니다.
정현진(Hyunjin Jeong) · 2026-06-21 · 9분 분량

한때 크롬은 전 세계 사용자 기기에서 동전 던지기를 켜 둔 채로 통계를 모았습니다.
각 브라우저가 서버로 보고서를 보내기 전에, 기기 안에서 먼저 비트 몇 개를 무작위로 뒤집었습니다. 서버에 도착하는 값은 이미 노이즈가 섞인 값이었습니다. 이 방식의 이름이 RAPPOR입니다.
그리고 2021년 2월 5일, 크롬은 이 인프라를 통째로 들어냈습니다. 한 변경 한 건이 125개 파일에서 4,985줄을 지웠습니다.1 로컬 차등 프라이버시의 모범 사례로 꼽히던 설계가 왜 끝까지 살아남지 못했는지, 그 자리를 무엇이 대신했는지가 이 칼럼의 질문입니다.
한 줄 요약 RAPPOR은 서버를 믿지 않고도 모집단 통계를 모으는 로컬 DP 설계였지만, 추정 오차가 보고 수의 제곱근에 비례해 커지는 구조 탓에 인구의 0.1%에 못 미치는 희귀 신호는 노이즈에 묻혔습니다. 셔플 모델은 가운데에 '섞는 사람'을 한 명 끼워 정확도와 스케일을 되살리는 대신, 그 셔플러가 정직하다는 신뢰 가정 하나를 새로 떠안습니다.
서버를 믿지 않고도 통계를 모으려는 야심
RAPPOR이 풀려던 문제는 분명합니다. 수억 대의 사용자 기기에서 통계를 모으되, 그 데이터를 받는 서버조차 개인을 들여다보지 못하게 하는 것입니다.
로컬 차등 프라이버시는 이 목표에 잘 맞는 모델입니다. 로컬 DP는 무작위화를 신뢰할 수 있는 제3자가 아니라 사용자 기기 안에서 직접 수행하는 방식입니다. 서버로 떠나기 전에 이미 노이즈가 섞이므로, 수집하는 쪽을 믿지 않아도 됩니다.
크롬에 실제로 탑재됐던 RAPPOR이 바로 이 구조였습니다. 보고서는 사용자 데이터를 바탕으로 편향시킨 무작위 데이터이며, 여러 사용자의 보고를 모으면 모집단은 배울 수 있어도 개별 사용자에 대해서는 거의 아무것도 알 수 없게 설계됐습니다.2 논문은 이 목표를 '클라이언트 데이터라는 숲은 연구하되 개별 나무는 들여다볼 수 없게 한다'고 표현합니다.3
여기서 매력은 신뢰 가정이 거의 없다는 점입니다. 일회성 수집이라도 공격자가 사전 지식을 얼마나 갖고 있든 무관하게, 각 응답은 ε-차등 프라이버시 보장으로 보호됩니다.3 야심 찬 설계였던 이유가 이것입니다.
랜덤 응답이라는 오래된 아이디어를 비트맵에 얹다
RAPPOR이 새로 발명한 것은 없습니다. 바탕에 깔린 통계 기법은 1965년에 나온 랜덤 응답(randomized response)입니다.4
랜덤 응답은 민감한 설문에서 응답자의 비밀을 지키려고 고안됐습니다. 응답자가 자기 손 안의 동전이나 주사위로 어느 질문에 답할지 스스로 정하므로, 오직 본인만 어느 질문에 답했는지 압니다. 그래서 예/아니오 응답에 낙인이 붙지 않으면서도 모집단 비율은 통계적으로 복원됩니다. 이 말은, 노이즈가 서버가 아니라 응답자 손에서 이미 섞인다는 뜻입니다. RAPPOR이 가져온 로컬 모델의 원형이 바로 여기입니다.
RAPPOR은 이 아이디어를 비트맵 위에 얹었습니다. 먼저 사용자의 값을 h개의 해시 함수로 크기 k짜리 블룸 필터(Bloom filter)에 해싱해 비트 배열로 만듭니다.5 그다음 무작위화를 두 단계로 나눠 적용합니다.
| 단계 | 무엇을 하는가 | 왜 필요한가 |
|---|---|---|
| 영구 랜덤 응답 | 각 비트를 확률 f로 동전 던지기로 덮어쓰고, 그 결과를 기억해 이후 모든 보고에 재사용 | 같은 값을 여러 번 보고해도 노이즈가 고정돼, 반복 관찰로 원값이 드러나는 것을 막음 |
| 순간 랜덤 응답 | 매 보고마다 영구 결과 위에 다시 확률적으로 비트를 켜서 새 보고값 생성 | 매번 똑같은 보고서가 나가지 않게 해, 보고서 자체가 추적용 식별자가 되는 것을 막음 |
표를 한 줄로 풀면 이렇습니다. 영구 단계는 장기 추적을 막고, 순간 단계는 보고서 하나가 지문이 되는 것을 막습니다.5 핵심은 서버가 손대기 전에, 기기 안에서 노이즈가 두 번 섞인다는 점입니다.
한 글자를 알아내려면 사용자가 몇 명 필요한가
여기서 함정이 생깁니다. 기기마다 노이즈를 넣으면 개인은 안전하지만, 정작 보고 싶은 통계도 같이 흐려집니다.
숫자로 보면 더 선명합니다. RAPPOR의 추정량은 분산이 보고 수에 비례해 커지고, 표준편차는 보고 수의 제곱근에 비례합니다.6 이 말은, 빈도 추정의 상대 오차가 보고 수의 제곱근에 반비례해 줄어든다는 뜻입니다. 정확도를 두 배로 높이려면 사용자 수를 약 네 배로 늘려야 한다는 계산이 여기서 나옵니다.
그래서 RAPPOR은 표본 크기 N에서 대략 N의 10분의 1만큼의 서로 다른 문자열만 안정적으로 잡아냅니다. 1억 건이면 약 1,000개, 100억 건이면 약 10,000개입니다.7 더 또렷한 기준도 있습니다. 어떤 값이 응답 인구의 0.1%를 넘는 빈도여야 신뢰 있게 발견됩니다.7
실제 사례가 이를 못 박습니다. 크롬 홈페이지 도메인을 수집할 때, 한 도메인이 RAPPOR 분석으로 잡히려면 그 빈도가 응답 인구의 0.1%를 넘어야 했습니다. 사용자 수로 환산하면, 같은 도메인을 1만 4천 명 넘게 보고해야 비로소 노이즈 위로 떠올랐습니다.7 100만 사용자 중 0.1%만 쓰는 기능이라면, 그 신호는 사실상 보이지 않습니다.
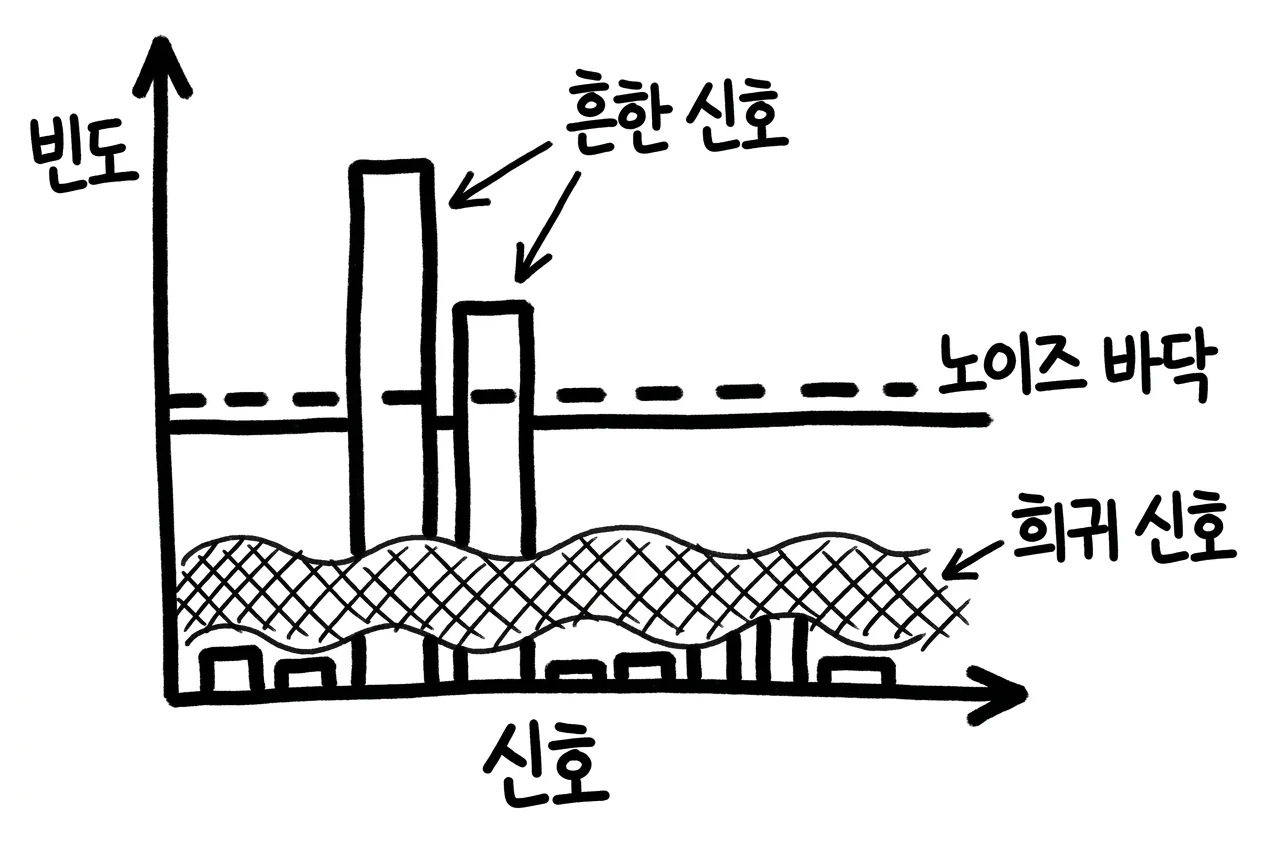
희귀한 값을 굳이 끌어내려 하면 더 큰 문제가 생깁니다. 빈도가 낮은 문자열을 노이즈에서 건지는 작업은 거짓 발견을 무더기로 만들어 내기 때문에, 현실적으로 불가능합니다.8 즉 이것은 엔지니어링을 더 다듬으면 풀리는 문제가 아니라, 노이즈 바닥 자체가 정한 한계입니다.
노이즈만 줄여서는 넘지 못하는 벽
이 한계가 RAPPOR만의 튜닝 실패였다면 노이즈를 더 깎으면 됐을 것입니다. 그러나 이것은 로컬 모델의 구조적 한계입니다.
이론은 두 갈래로 이를 받쳐 줍니다.
- 로컬 모델의 학습 능력은 통계 질의(SQ) 모델에 묶여 있습니다. 로컬(랜덤 응답) 방식으로 배울 수 있는 개념 집합은 SQ 모델로 배울 수 있는 것과 정확히 일치합니다.9
- 차원이 커질수록 손해가 빠르게 불어납니다. 고차원 평균 추정에서 로컬 프라이버시의 오차는 중앙·비공개 추정보다 차원 수만큼 더 곱해진 크기로 커집니다.10
첫째 갈래부터 풀어 봅니다. SQ는 PAC보다 좁은 학습 틀이므로, 노이즈를 아무리 잘 조절해도 로컬 방식은 중앙 모델만큼 배울 수 없습니다. 게다가 대화형 로컬 방식이 비대화형 방식보다 엄밀히 더 강한데,9 RAPPOR처럼 한 번만 노이즈를 넣어 보내는 방식은 이미 제한된 모델 안에서도 가장 약한 구석에 자리합니다.
둘째 갈래는 차원의 저주입니다. d차원 평균을 추정할 때 로컬 프라이버시의 최소최대 오차는 차원 수 d만큼 한 번 더 곱해진 크기로 커집니다. 차원 하나가 늘 때마다 오차가 배로 불어난다는 뜻입니다. 같은 연구는 이를 표본 크기 손실로도 정리합니다. 로컬 프라이버시는 쓸 수 있는 유효 표본 수를 차원에 비례해 깎아 내며,10 이렇게 버려진 데이터는 노이즈 조절로는 되찾을 수 없습니다. 중앙 모델과 셔플 모델이 비켜 가려는 벽이 바로 이것입니다.
한 분석은 이 손해의 정체를 한 문장으로 정리합니다. 로컬 DP 프로토콜이 안고 있는 높은 노이즈와 제곱근 오버헤드는, 사실 그 프로토콜이 중앙 모델 기준으로는 훨씬 더 강하게 보호하고 있었던 대가입니다.11 손해처럼 보였던 제곱근 비용은, 알고 보면 더 강한 보장의 청구서였습니다.
가운데에 섞는 사람을 한 명 두면 달라지는 것
전환점은 가운데에 단계 하나를 끼우는 데서 옵니다. 보고서를 받아 익명화하고 뒤섞는 '셔플러(shuffler)'입니다. 이 구조가 인코드-셔플-분석(Encode-Shuffle-Analyze), 줄여서 ESA이고, 이를 구현한 시스템이 Prochlo입니다.
셔플러는 클라이언트 인코더 바로 다음에 놓여, 보고서에 묻은 타임스탬프, 출발지 IP, 경로 같은 암묵적 메타데이터를 전부 벗겨 냅니다.12 그리고 데이터를 모아 두었다가 무작위로 순서를 섞은 뒤에야 묶음으로 내보냅니다. 이 무작위 순서 섞기가 한 사용자의 데이터 조각들 사이의 직접적인 연결을 끊어, 데이터를 군중 속에 숨깁니다.13
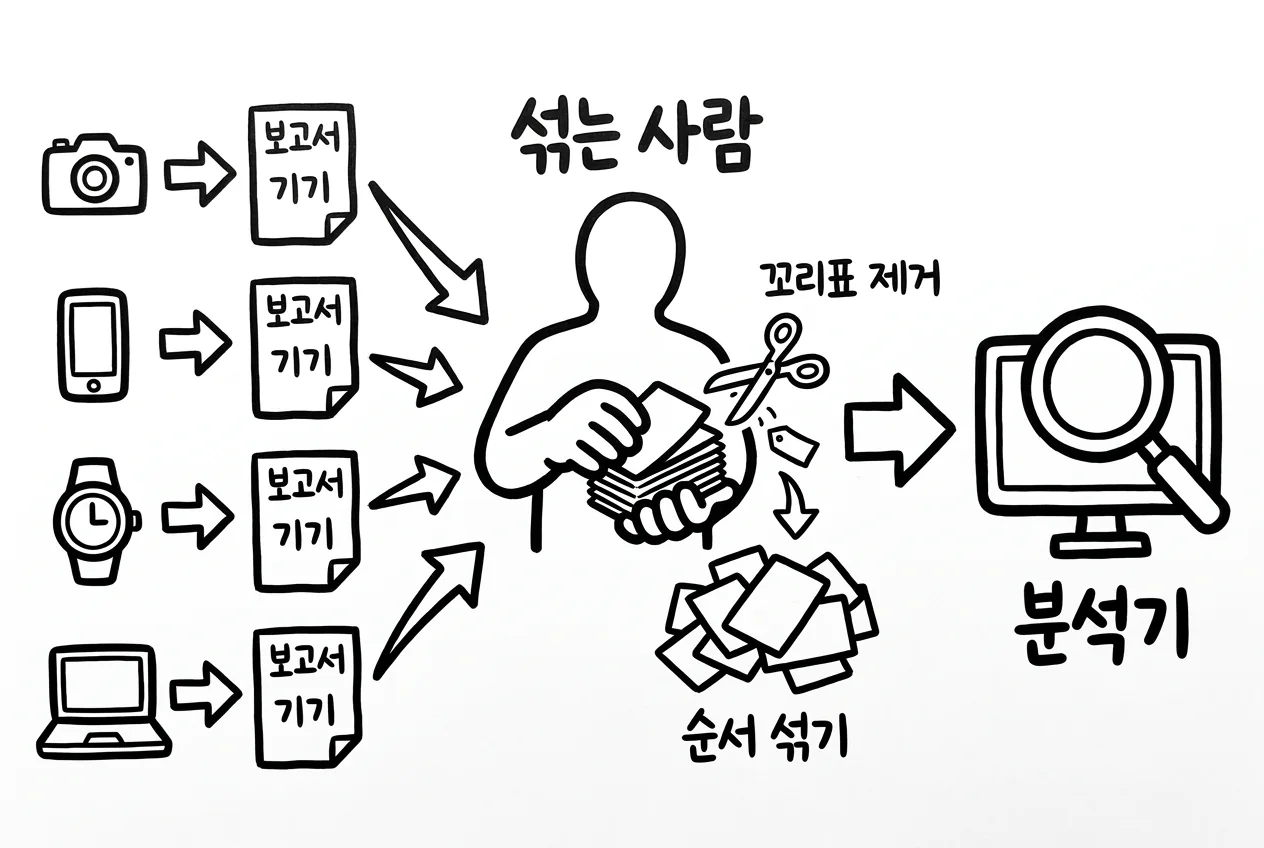
군중 속 익명성이라는 직관이 그대로 수학이 됩니다. 셔플에 의한 증폭(amplification by shuffling) 정리는, 순서에 무관한 어떤 알고리즘이 ε-로컬 DP를 만족하면, n명에 걸쳐 셔플한 뒤에는 ε에 로그 항을 곱하고 n의 제곱근으로 나눈 크기의 중앙 DP를 만족한다고 말합니다.11 이 말은, 최악의 경우 프라이버시 비용이 사용자 수의 제곱근만큼 줄어든다는 뜻입니다. 각 기기는 약한 로컬 노이즈만 넣어도, 모집단 단위에서는 중앙 모델에 가까운 보장이 나오는 까닭이 이것입니다.
셔플 모델이 RAPPOR과 무관한 새 시스템이 아니라는 점도 분명합니다. ESA 설계는 크롬에서 RAPPOR을 만들고 운영한 경험에서 직접 나왔습니다.14 앞 절에서 본 제곱근 한계를, 같은 사람들이 다른 방식으로 비켜 간 셈입니다.
셔플 모델이 공짜로 주는 것은 아닙니다
증폭은 공짜가 아닙니다. 이 보장은 다음 두 조건 위에서만 성립합니다.
- 보고서가 정말로 익명화될 수 있어야 합니다. 증폭 정리가 성립하려면 보고서들이 서로를 구별할 만한 특징을 갖지 않아야 하고, 모두 같은 로컬 무작위화기를 써야 합니다.15
- 셔플러가 정직하게 섞어야 합니다. 형식화된 분석에 따르면 여러 서버 중 단 하나라도 정직하게 섞으면 전체가 균등 무작위 순열이 되어 보장이 유지됩니다.16
순열의 정직함이 보장을 떠받치는 가정입니다.
여기서 경계가 분명해집니다. 만약 셔플러와 분석기가 함께 무너지면 어떻게 될까요. 공격자는 누가 무엇을 냈는지 그대로 보게 됩니다. ESA를 쓰지 않은 수집 서비스를 장악한 것과 다를 바 없습니다. 그런 상황에서도 기기에서 한 인코딩이 일부 보호는 남기지만,17 그것은 결국 RAPPOR식 로컬 노이즈가 주는 보호, 즉 원래의 약한 로컬 ε로 되돌아간 보호입니다.
셔플의 힘에도 한계가 있습니다. 셔플 모델의 능력은 로컬과 중앙의 정확히 사이에 놓입니다. 한 자연스러운 제약 아래에서, 널리 연구된 선택 문제를 셔플 방식으로 풀려면 중앙 모델보다 표본 수가 지수적으로 더 듭니다.18 셔플이 모든 과제에서 중앙 모델의 힘을 완전히 회복시켜 주지는 않는다는 뜻입니다.
그래서 이 이야기의 범위도 분명히 해야 합니다. 핵심은 'RAPPOR이 깨졌다'가 아니라, '같은 정확도를 더 싼 노이즈로 얻을 길이 생겼다'입니다. 증폭 결과는 기존 로컬 DP 배포들이 익명화를 전제로 하면 광고된 ε보다 실제 프라이버시 비용이 더 낮을 수 있음을 보였고, 보고서 하나하나에 대한 로컬 보장은 그 보고서가 공개되더라도 그대로 유지됩니다.19
그래서 크롬은 RAPPOR을 내렸습니다
폐기는 극적인 사건이 아니었습니다. 2021년 2월 5일 변경 당시, RAPPOR으로 여전히 보고되던 지표는 소수만 남아 있었고 제거해도 무방함이 확인됐습니다.1 인프라가 가동 중이었다는 사실 자체는 분명합니다. 폐기 직전까지도 크롬 소스 트리의 components/rappor 디렉터리에는 서비스 구현, 블룸 필터 유틸리티, 메트릭, 업로더 등 다수의 실제 파일이 존재했습니다.20
운영하던 팀의 진단도 같은 방향을 가리킵니다. Prochlo 논문은 로컬 DP가 봉우리가 뾰족한 멱법칙 분포에서 가장 빈번한 원소를 재는 데만 잘 맞아 적용 범위가 크게 제한된다고 직접 밝힙니다. 또 로컬 DP로 모은 데이터는 불투명하고 고정돼 있어 탐색적 분석이나 수작업 검증이 불가능하고, 기존 엔지니어링 도구·프로세스와도 맞지 않는다고 지적합니다.21
스케일 숫자는 더 가혹합니다. app과 API 조합마다 또렷한 신호를 얻으려면, 로컬 DP에서는 비현실적인 양의 데이터가 필요합니다. 표준편차가 보고 수의 제곱근에 비례해 커지는 데다 실제 노이즈는 거기서 한 자릿수 더 크기 때문에, 필요한 양은 10만의 제곱, 즉 1조 명의 보고에 이릅니다.22 지구 인구를 한참 넘는 숫자입니다.
전환의 손익은 한 표로 정리됩니다.
| 모델 | 신뢰 가정 | 정확도·스케일 | 한 줄 평 |
|---|---|---|---|
| 로컬 DP (RAPPOR) | 수집 서버를 안 믿어도 됨 | 제곱근 오버헤드로 막힘, 희귀 신호 소실 | 보호는 강하나 통계가 안 나옴 |
| 셔플 모델 (ESA) | 셔플러가 정직하다는 가정 1개 추가 | 증폭으로 중앙 수준에 근접 | 신뢰 가정 하나로 정확도를 되삼 |
| 중앙 DP | 분석 주체를 신뢰 | 노이즈 최소, 가장 정확 | 가장 정확하나 가장 많이 믿어야 함 |
크롬이 로컬 RAPPOR을 내린 뒤 표준이 된 대안 스택은 google/differential-privacy 라이브러리입니다. ε- 및 (ε, δ)-DP 통계를 만들고, C++·Go·Java 빌딩 블록과 함께 인원·합계·평균·분위수 집계, 라플라스·가우시안 메커니즘, 임계 처리, 프라이버시 예산을 추적하는 회계 도구, Apache Beam 기반 프레임워크를 제공합니다. 핵심 구성요소는 연구뿐 아니라 프로덕션 용도에도 적합하다고 명시됩니다.23
정리하면 크롬의 결정은 RAPPOR이 틀렸다는 선언이 아닙니다. 신뢰 가정 하나를 더 받아들이는 대신 정확도와 스케일을 되찾는 교환이 더 낫다는 판단이었습니다. 같은 통계를 더 싼 노이즈로 얻을 길이 열리자, 비싼 노이즈를 켜 두던 옛 인프라는 조용히 자리를 비켰습니다.
참고 문헌
Footnotes
-
Chromium CL 2672923, "Remove RAPPOR reporting infrastructure" (chromium/src, 2021-02-05, author Alexei Svitkine, bug 1016906; 125개 파일, 38줄 추가·4,985줄 삭제). https://groups.google.com/a/chromium.org/g/blink-reviews/c/McuceO_WhA0 ↩ ↩2
-
Chromium,
components/rappor/README.md(commit 142b98e). https://chromium.googlesource.com/chromium/src/+/142b98e4d3b296b478eb5e549edb3ab2797a5f52/components/rappor/README.md ↩ -
Ú. Erlingsson, V. Pihur, A. Korolova, "RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response," ACM CCS 2014. https://arxiv.org/abs/1407.6981 ↩ ↩2
-
RAPPOR 논문은 이 기법을 1965년 랜덤 응답(S. L. Warner, "Randomized response: A survey technique for eliminating evasive answer bias," Journal of the American Statistical Association, 60(309):63–69, 1965, RAPPOR 참고문헌 [27])에 명시적으로 귀속합니다. Erlingsson, Pihur & Korolova, "RAPPOR," ACM CCS 2014, §1. https://arxiv.org/abs/1407.6981 ↩
-
Erlingsson, Pihur & Korolova, "RAPPOR," ACM CCS 2014, §1 (Bloom filter encoding, permanent/instantaneous randomized response). https://arxiv.org/abs/1407.6981 ↩ ↩2
-
Erlingsson, Pihur & Korolova, "RAPPOR," ACM CCS 2014, Appendix "Deriving Limits on Learning." https://arxiv.org/abs/1407.6981 ↩
-
Erlingsson, Pihur & Korolova, "RAPPOR," ACM CCS 2014, §4.2·§5.4 (N/10 rule, 0.1% floor, ~14,000 clients for Chrome homepage domains). https://arxiv.org/abs/1407.6981 ↩ ↩2 ↩3
-
Erlingsson, Pihur & Korolova, "RAPPOR," ACM CCS 2014, §6 "Attack Models and Limitations." https://arxiv.org/abs/1407.6981 ↩
-
S. Kasiviswanathan, H. Lee, K. Nissim, S. Raskhodnikova, A. Smith, "What Can We Learn Privately?," FOCS 2008. https://arxiv.org/abs/0803.0924 ↩ ↩2
-
J. Duchi, R. Rogers, "Lower Bounds for Locally Private Estimation via Communication Complexity," COLT 2019. https://arxiv.org/abs/1902.00582 ↩ ↩2
-
Ú. Erlingsson, V. Feldman, I. Mironov, A. Raghunathan, K. Talwar, A. Thakurta, "Amplification by Shuffling: From Local to Central Differential Privacy via Anonymity," SODA 2019. https://arxiv.org/abs/1811.12469 ↩ ↩2
-
A. Bittau, Ú. Erlingsson, et al., "Prochlo: Strong Privacy for Analytics in the Crowd," SOSP 2017, §3.3 Shuffler. https://arxiv.org/abs/1710.00901 ↩
-
Bittau et al., "Prochlo," SOSP 2017, §3.3 (random reordering hides data in the crowd). https://arxiv.org/abs/1710.00901 ↩
-
Bittau et al., "Prochlo," SOSP 2017, §1 (ESA informed by Chrome RAPPOR experience). https://arxiv.org/abs/1710.00901 ↩
-
Erlingsson, Feldman, Mironov, Raghunathan, Talwar & Thakurta, "Amplification by Shuffling," SODA 2019, §1.2 (anonymizability precondition). https://arxiv.org/abs/1811.12469 ↩
-
A. Cheu, A. Smith, J. Ullman, D. Zeber, M. Zhilyaev, "Distributed Differential Privacy via Shuffling," EUROCRYPT 2019 (single honest shuffler suffices). https://arxiv.org/abs/1808.01394 ↩
-
Bittau et al., "Prochlo," SOSP 2017, §3.1 (shuffler+analyzer compromise reverts to encoder-level protection). https://arxiv.org/abs/1710.00901 ↩
-
Cheu, Smith, Ullman, Zeber & Zhilyaev, "Distributed Differential Privacy via Shuffling," EUROCRYPT 2019 (shuffle model strictly between local and central). https://arxiv.org/abs/1808.01394 ↩
-
Erlingsson et al., "Amplification by Shuffling," SODA 2019, Abstract·§1 (scope: cheaper privacy cost, per-report local guarantee holds). https://arxiv.org/abs/1811.12469 ↩
-
Chromium source tree,
components/rapporat tag 71.0.3553.2. https://chromium.googlesource.com/chromium/src/+/71.0.3553.2/components/rappor/ ↩ -
Bittau et al., "Prochlo," SOSP 2017, §2.2 (local DP operational limits). https://arxiv.org/abs/1710.00901 ↩
-
Bittau et al., "Prochlo," SOSP 2017, §2.2 (one trillion users figure for local DP). https://arxiv.org/abs/1710.00901 ↩
-
Google, differential-privacy library, README. https://github.com/google/differential-privacy ↩