가명정보와 익명정보 구분이 헷갈리는 진짜 이유는 '결합 가능성'입니다
개인정보 보호법의 가명정보와 익명정보는 둘 다 '다른 정보와의 결합 가능성'이라는 가정형 판단 위에 있어 데이터만 봐서는 구분할 수 없습니다. 차등 프라이버시 출력도 자동으로 익명정보가 되지는 않습니다.
정현진(Hyunjin Jeong) · 2026-07-03 · 10분 분량

‘익명처리가 끝났습니다. 동의 없이 제휴사에 넘겨도 됩니다.’
데이터팀의 말에 법무팀이 고개를 젓습니다.
‘아닙니다. 이건 익명정보가 아니라 가명정보입니다. 개인정보 보호법이 그대로 적용됩니다.’
회의실 화면에 떠 있는 것은 이름, 주민등록번호, 전화번호를 전부 지운 병원 데이터셋입니다. 남은 열은 생년월일, 성별, 거주지역뿐입니다. 같은 표를 놓고 두 팀의 판정이 갈렸습니다.
누가 무능해서 생기는 일이 아닙니다. NIST 공식 보고서조차 ‘비식별화’와 ‘익명화’라는 용어가 문헌마다 다르게 쓰인다고 지적할 만큼1, 이 경계는 원래 흐릿합니다. 그리고 한국 개인정보 보호법의 조문을 그대로 읽어 봐도 흐릿함은 사라지지 않습니다.
한 줄 요약
개인정보 보호법에서 가명정보는 법 안에, 익명정보는 법 밖에 있지만, 두 정의 모두 ‘다른 정보와 결합하면 알아볼 수 있는가’라는 가정형 판단 위에 서 있어 데이터의 겉모습만으로는 판정할 수 없습니다. 판정은 데이터가 누구에게 어떤 환경으로 나가는지까지 묶어서 내려야 하고, 차등 프라이버시를 적용했다는 사실만으로 자동으로 익명정보가 되지도 않습니다.
가명정보는 법 안에, 익명정보는 법 밖에 있습니다
개인정보 보호법 제2조 제1호는 개인정보를 세 갈래로 정의합니다. 이름처럼 그 자체로 개인을 알아볼 수 있는 정보(가목), 그 자체로는 알아볼 수 없어도 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보(나목), 그리고 가명정보(다목)입니다2.
가명정보의 정의는 이렇게 쓰여 있습니다.
‘가명처리함으로써 원래의 상태로 복원하기 위한 추가 정보의 사용ㆍ결합 없이는 특정 개인을 알아볼 수 없는 정보’2
가명정보는 추가 정보와 결합하지 않으면 누구인지 알 수 없게 가공했지만 여전히 개인정보의 한 유형으로 남는, 법 안의 정보입니다. 가명처리는 개인정보의 일부를 삭제하거나 일부 또는 전부를 대체하는 등의 방법으로 그런 상태를 만드는 처리입니다2.
반면 익명정보의 자리는 제58조의2입니다.
‘이 법은 시간ㆍ비용ㆍ기술 등을 합리적으로 고려할 때 다른 정보를 사용하여도 더 이상 개인을 알아볼 수 없는 정보에는 적용하지 아니한다.’2
이 조문은 2020년 2월 4일 이른바 데이터 3법 개정으로 신설됐습니다. 법문에는 ‘익명정보’라는 단어 자체가 없습니다. 조건을 충족한 정보는 이름을 얻는 대신 법 밖으로 나갑니다.
법 스스로 위계도 정해 두었습니다. 제3조 제7항은 익명처리로 수집 목적을 달성할 수 있으면 익명으로, 그럴 수 없을 때에만 가명으로 처리하라고 요구합니다2. 익명이 기본값이고 가명이 차선이라는 구조입니다.
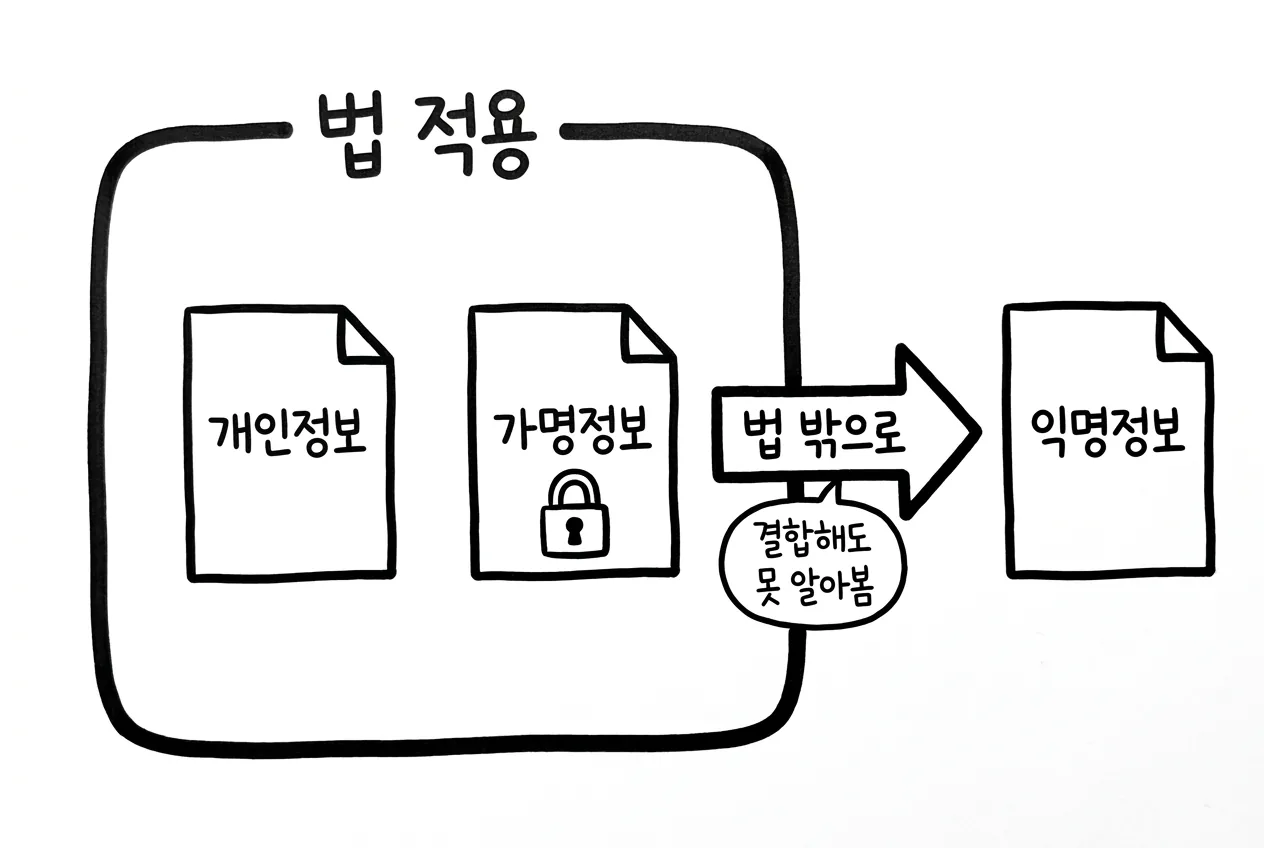
판정 하나가 규제 강도를 하늘과 땅으로 가릅니다
가명정보로 판정되면 특례가 붙습니다. 통계작성, 과학적 연구, 공익적 기록보존 목적에 한해 정보주체의 동의 없이 처리할 수 있지만(제28조의2), 그 대가로 의무가 따라옵니다2.
| 구분 | 가명정보 | 익명정보 |
|---|---|---|
| 법적 지위 | 개인정보의 한 유형(법 적용) | 법 적용 제외(제58조의2) |
| 동의 없는 처리 | 통계작성·과학적 연구·공익적 기록보존 목적에 한함 | 제한 없음 |
| 다른 기관 데이터와 결합 | 지정된 결합전문기관에서만, 반출 시 승인 필요 | 제한 없음 |
| 안전조치 | 추가 정보 분리 보관 등 기술적·관리적·물리적 조치 의무 | 해당 없음 |
| 재식별 시도 | 금지, 위반 시 과징금·형사처벌 | 해당 없음 |
의무의 무게는 가볍지 않습니다. 서로 다른 기관의 가명정보 결합은 개인정보보호위원회 등이 지정한 결합전문기관만 수행할 수 있고, 결합된 정보를 밖으로 내보내려면 기관장의 승인까지 받아야 합니다(제28조의3)2. 원상 복원용 추가 정보는 별도로 분리해 보관해야 하고(제28조의4), 특정 개인을 알아보려는 목적의 처리는 금지되며 그런 정보가 생성되면 즉시 중지하고 회수·파기해야 합니다(제28조의5)2.
재식별 금지를 어기면 전체 매출액의 3% 이하 과징금이 부과될 수 있고, 형사처벌로는 5년 이하의 징역 또는 5천만원 이하의 벌금이 따릅니다(제64조의2, 제71조)2. 대신 가명정보에는 열람·정정·삭제·처리정지 같은 정보주체의 권리 일부가 적용되지 않는(제28조의7), ‘법 안이지만 완화된’ 중간 지위가 주어집니다2.
익명정보로 판정되면 이 전부가 사라집니다. 그래서 실무자는 ‘익명’ 판정 쪽으로 기울고 싶어집니다. 문제는 그 판정 기준이 생각만큼 견고하지 않다는 데 있습니다.
두 정의 모두 ‘결합 가능성’이라는 가정 위에 서 있습니다
핵심 문구를 나란히 놓아 보면 공통분모가 드러납니다.
- 개인정보(제2조 제1호 나목): 다른 정보와 ‘쉽게 결합하여’ 알아볼 수 있는 정보. 쉽게 결합할 수 있는지는 다른 정보의 입수 가능성, 시간, 비용, 기술을 합리적으로 고려해 판단합니다2.
- 가명정보(다목): 추가 정보의 ‘사용ㆍ결합 없이는’ 알아볼 수 없는 정보2.
- 익명정보(제58조의2): 시간·비용·기술을 합리적으로 고려할 때 ‘다른 정보를 사용하여도’ 알아볼 수 없는 정보2.
셋 다 ‘지금 이 표에 무엇이 적혀 있는가’가 아니라 ‘누군가 다른 정보를 들고 와서 결합을 시도하면 어떻게 되는가’라는, 미래의 결합 시도를 가정한 질문입니다.
데이터만 뚫어지게 들여다봐서는 답이 나오지 않는 이유가 여기 있습니다. 판단 재료의 절반이 데이터 밖에 있기 때문입니다. 결합에 쓰일 다른 정보가 세상에 얼마나 굴러다니는지, 결합에 드는 시간과 비용이 얼마인지는 표 안에 적혀 있지 않습니다.
EU도 같은 문제를 겪었습니다. EU의 자문기구였던 제29조 작업반(WP29)은 2014년 익명화 기법 의견서(WP216)에서, 익명화가 충분히 견고한지를 ‘합리적으로 사용될 가능성이 있는 수단’ 기준으로 심사하되 식별 가능성은 사안별 맥락과 상황에 직접 좌우된다고 명시했습니다3. 연구·도구·계산 능력이 계속 진화하므로 ‘식별이 더 이상 불가능한 상황’을 망라해 열거하는 일은 가능하지도 유용하지도 않다고까지 적었습니다3.
한국 규제기관의 실무 해석도 같은 방향입니다. 개인정보보호위원회의 가명정보 처리 가이드라인(2026년 3월 개정판)은 추가정보를 삭제해 그 자체로는 개인을 알아볼 수 없게 된 가명정보라도, 익명정보인지는 시간·비용·기술을 합리적으로 고려해 별도로 판단해야 한다고 답합니다4.
같은 표라도 받는 쪽이 무엇을 들고 있는지에 따라 판정이 달라진다는 뜻입니다. NIST 보고서의 표현을 빌리면, 데이터에 어떤 효용이라도 남아 있는 한 원래 개인에게 다시 연결될 가능성은 아무리 희박해도 존재하고, 그 위험은 추정하기도 어렵습니다1.
재식별은 가정이 아니라 이미 벌어진 일입니다
‘결합하면 알아볼 수 있는가’가 탁상공론처럼 들린다면, 숫자를 보는 편이 빠릅니다.
회의실 장면의 생년월일·성별·거주지역 같은 값을 준식별자(quasi-identifier)라고 부릅니다. 준식별자는 그 자체로는 개인을 식별하지 못하지만, 다른 정보와 연결되면 개인을 식별하게 만드는 값입니다1.
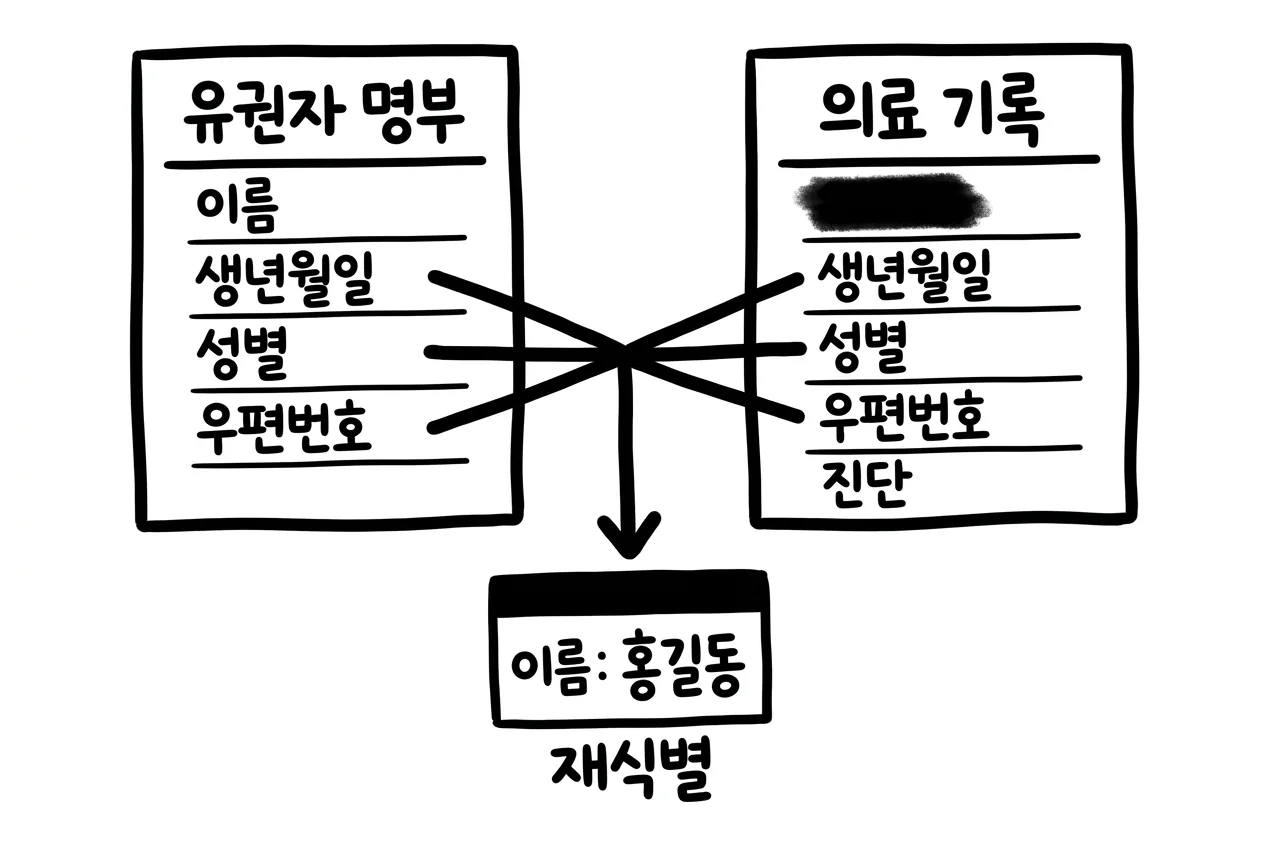
1990년 미국 인구총조사 데이터를 분석한 카네기멜런대학의 연구에 따르면, 미국 인구의 87%(2억 4,800만 명 중 2억 1,600만 명)가 5자리 우편번호, 성별, 생년월일 세 값만으로 유일하게 특정될 가능성이 높았습니다5. 지역 단위를 도시로 넓혀도 53%, 카운티로 넓혀도 18%가 남습니다5.
이 연구는 계산에 그치지 않았습니다. 연구자는 20달러에 매사추세츠주 케임브리지시의 유권자 명부(이름·주소·우편번호·생년월일·성별 포함)를 구입했고, 이를 이름만 지운 병원 퇴원 데이터와 결합하면 진단·처치·투약 기록이 실명에 연결된다는 사실을 확인했습니다5. NIST SP 800-226이 공식 기록으로 인용하듯, 1997년 연구자들은 실제로 성별·우편번호·생년월일을 유권자 명부와 결합해 비식별 의료기록에서 매사추세츠 주지사 윌리엄 웰드를 재식별했습니다6.
넷플릭스 사건은 규모를 키웠습니다. 넷플릭스가 추천 알고리즘 대회(Netflix Prize)를 위해 공개한 구독자 50만 명 규모의 ‘익명’ 영화 평점 데이터에서, 텍사스대학 연구팀이 공개 영화 사이트 IMDb의 평점을 배경지식 삼아 알려진 사용자들의 넷플릭스 기록을 식별하고 정치 성향 같은 민감 정보까지 드러냈습니다7. 필요한 배경지식은 놀랄 만큼 적었습니다.
| 공격자가 아는 정보 | 유일하게 식별되는 비율 |
|---|---|
| 평점 8개(그중 2개는 틀려도 됨) + 14일 오차의 날짜 | 레코드의 99% |
| 평점 2개 + 3일 오차의 날짜 | 68% |
| 날짜 없이, 상위 500위 밖 영화 8편 중 6편 | 구독자의 84% |
흔하지 않은 영화일수록 더 잘 드러난다는 마지막 줄이 특히 아픕니다7. 결합에 쓰일 ‘다른 정보’가 유권자 명부처럼 20달러에 팔리거나 IMDb처럼 공개되어 있는 세상에서는, 어제의 익명이 오늘은 가명조차 못 될 수 있습니다.
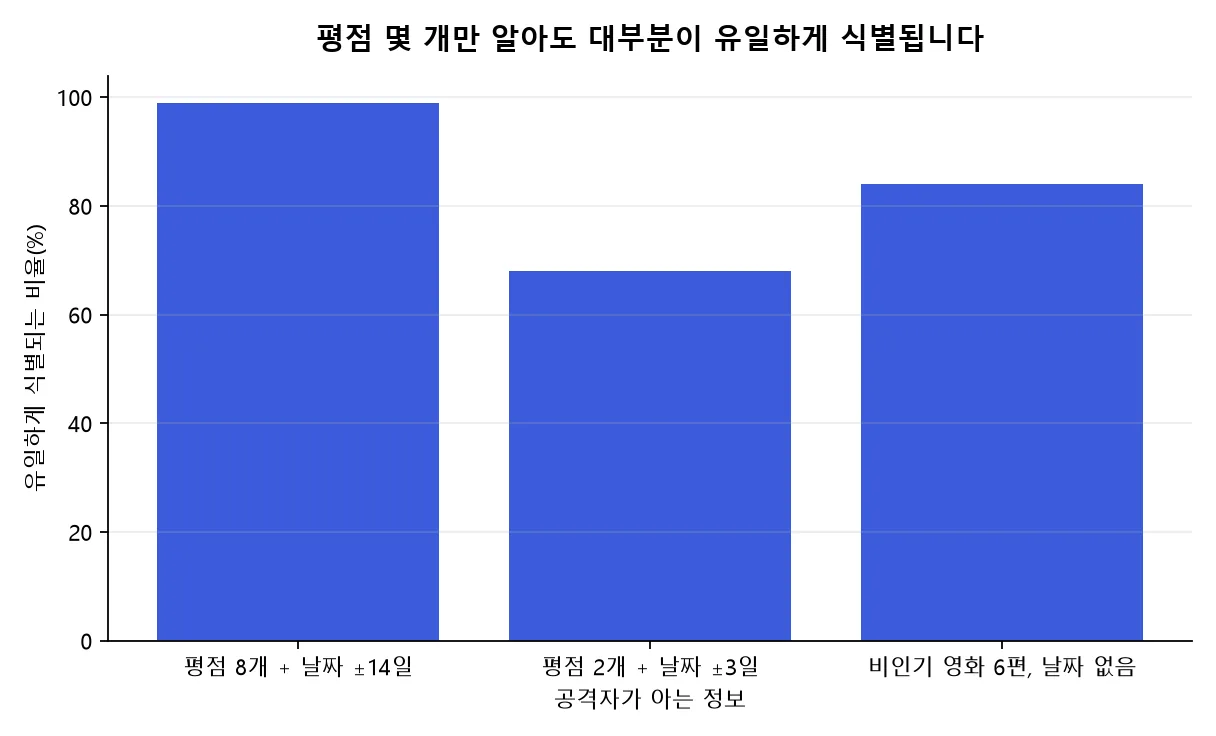
넷플릭스 평점 데이터 재식별 결과. 앞의 두 값은 레코드 기준, 마지막 값은 구독자 기준 비율입니다.
차등 프라이버시는 상태가 아니라 과정을 보장합니다
여기서 차등 프라이버시(differential privacy, DP)의 위치를 잡을 수 있습니다. 차등 프라이버시는 어떤 한 사람의 자료가 데이터에 들어가든 빠지든 결과가 거의 달라지지 않도록, 계산 과정에 무작위 노이즈를 넣는 수학적 기준입니다. 결과가 사람 한 명에 좌우되지 않으니, 결과만 보고 특정 개인이 들어 있었는지 가려내기 어려워집니다.
가명·익명 구분과는 축이 다릅니다. 가명과 익명은 ‘이 데이터셋이 지금 어떤 상태인가’를 묻는 분류이고, 차등 프라이버시는 ‘이 결과를 만들어 낸 처리 과정이 무엇을 보장하는가’를 묻는 기준입니다. DP의 표준 교과서는 이 성질 덕분에 결합 공격이 무력화된다고 설명합니다. 보장이 데이터 접근 과정의 성질이라서, 공격자가 IMDb 같은 보조 정보를 들고 있어도 달라지지 않기 때문입니다8. NIST SP 800-226도 차등 프라이버시가 기법이나 절차가 아니라 ‘정의’라는 점을 비식별화와의 결정적 차이로 꼽고, 보조 데이터를 이용한 공격을 포함한 모든 잠재적 공격에 대한 보호를 제공한다고 설명합니다6.
규제기관의 평가도 있습니다. WP29는 효과적인 익명화가 막아야 할 위험을 세 가지로 구체화했습니다3.
- 특정(singling out): 데이터셋에서 한 개인을 골라내는 것
- 연결(linkability): 같은 사람의 레코드 두 개를, 한 데이터셋 안에서든 서로 다른 데이터셋 사이에서든 잇는 것
- 추론(inference): 데이터셋으로부터 개인에 대한 정보를 미루어 알아내는 것
그리고 검토한 기법들의 강약점 비교표(Table 6)에서 특정·연결 위험이 ‘남지 않을 수 있음’으로 분류된 기법은 차등 프라이버시가 유일했습니다. 가명처리는 세 위험이 모두 ‘남는다’로, 해싱도 특정·연결 위험은 ‘남는다’로 평가됐습니다3.
학계는 한 걸음 더 나갔습니다. PNAS에 실린 한 연구(2020)는 GDPR의 ‘특정’ 개념을 술어 기반 특정(predicate singling out)이라는 수학적 정의로 형식화한 뒤, 차등 프라이버시는 이 공격에 대한 보안을 함의하지만 k-익명성은 함의하지 않음을 증명했습니다9. 이 연구의 출발점 자체가 시사적입니다. 법적 사고와 수학적 사고 사이의 개념적 간극 때문에, 어떤 기술이 법적 기준을 충족하는지가 불확실하다는 진단입니다9.
여기까지만 보면 ‘DP로 처리했으니 익명정보’라는 결론이 나올 것 같습니다. 하지만 바로 여기서 멈춰야 합니다.
DP를 붙였다고 자동으로 익명정보가 되지는 않습니다
같은 WP29 의견서에 반대 방향의 판단도 함께 실려 있습니다. 차등 프라이버시 기법은 원본 데이터를 바꾸지 않으므로, 원본이 남아 있는 한 개인정보처리자는 DP 질의 결과에서도 개인을 식별할 수 있고, 따라서 그 결과 역시 개인정보로 봐야 한다고 판단했습니다3.
경계 조건은 그 밖에도 여럿입니다.
ε이 크면 보장이 무의미할 수 있습니다. NIST SP 800-226은 큰 ε 값이 의미 있는 프라이버시를 제공하지 못할 수 있다고 명시적 위험으로 경고하면서도, ε 선택의 구체적 지침은 제공하지 않고 열린 연구 문제로 남겨 두었습니다6. ε은 노이즈의 양을 조절하는 손잡이인데, 손잡이를 느슨하게 풀면 이름표만 DP인 결과가 나옵니다.
보장은 DP를 통과한 그 출력에만 붙습니다. 같은 원본에서 DP 없이 나간 다른 통계나 공개물이 있다면, DP를 썼다는 사실이 그쪽 위험을 전혀 완화해 주지 않습니다6.
원본 데이터셋의 의무는 그대로 남습니다. 대부분의 DP 기법은 노이즈 없는 원본에 직접 접근해야 하므로, 원본이 유출되면 DP 보장은 무의미해집니다. 저장 중이든 계산 중이든 원본은 강한 보안 조치로 보호해야 합니다6.
‘DP를 썼다’는 말은 하나의 보장이 아닙니다. 2006년 처음 제안된 이후 서로 다른 시나리오와 공격자 모델에 맞춘 수많은 변형·확장이 나왔고, 한 서베이 논문은 원 정의의 어떤 요소를 수정했는지에 따라 이를 7개 범주로 분류했습니다10. 어떤 변형을, 어떤 파라미터로, 어떤 보호 단위에 적용했는지까지 말해야 보장이 특정됩니다.
한국법의 판정도 자동이 아닙니다. 개인정보보호위원회 가이드라인은 그 자체로 개인을 알아볼 수 없게 된 정보라도 익명정보 여부는 별도로 판단하라고 요구하고4, 적정한 처리 수준은 데이터의 특성과 처리 목적·환경, 상황과 맥락에 따라 달라진다고 못박습니다4. 특정 시·구에 직업이 국회의원인 사람이 1명뿐이라면 그 정보는 적절히 가명처리된 것이 아니라는 예시까지 실려 있습니다4.
그래서 ‘차등 프라이버시로 처리한 출력은 가명정보인가 익명정보인가’라는 물음에는 조문만으로 확답할 수 없습니다. ε과 보호 단위, 원본 보유 여부, 공개 범위까지 묶어 사안별로 따져야 하고, 최종 판정은 법률 검토와 규제기관 판단의 영역입니다.
판정 전에 스스로 물어볼 질문 다섯 가지
개인정보보호위원회 가이드라인은 가명처리를 단발성 기술 처리가 아니라 5단계 절차로 규정합니다4.
- 사전준비: 처리 목적을 구체적으로 설정
- 위험성 검토: 데이터와 처리 환경의 재식별 위험 평가
- 가명처리: 위험 수준에 맞는 처리 수행
- 적정성 검토: 처리 목적과 결과의 적정성 확인
- 안전한 관리: 활용하는 동안 재식별 위험을 지속 관리
이 절차 위에 지금까지의 논의를 얹으면, 판정 전에 확인할 질문이 다섯 가지로 압축됩니다.
| 질문 | 왜 중요한가 |
|---|---|
| 목적이 통계작성·과학적 연구·공익적 기록보존 중 무엇이고, 얼마나 구체적인가 | ‘연구’, ‘통계’처럼 추상적인 목적 설정은 특례 처리로 인정되지 않습니다4 |
| 데이터가 누구에게, 어떤 환경으로 나가는가 | 내부 활용은 저위험, 통제 가능한 제3자 제공은 중위험, 통제 불가능한 제3자 제공은 고위험으로 평가됩니다4 |
| 불특정 다수에게 공개하는가 | 가명정보의 공개는 사실상 제한되며, 공개하려면 익명정보로 처리하는 것이 원칙입니다4 |
| 한 명뿐인 조합(특이값)이 있는가 | 시·구에 1명뿐인 직업처럼 홀로 남는 조합은 그 자체로 식별 위험입니다4 |
| DP를 썼다면 ε은 얼마이고, 보호 단위는 무엇인가 | DP 보장의 실체는 프라이버시 파라미터와 보호 단위가 함께 결정합니다6 |
다음 회의에서 ‘익명처리 됐으니 그냥 쓰면 됩니다’라는 말이 나오면, 표의 겉모습 대신 이 질문들부터 확인해야 합니다. 가명과 익명의 경계는 데이터 안이 아니라, 그 데이터가 놓일 세상 쪽에 그어져 있기 때문입니다.
참고 문헌
Footnotes
-
Simson Garfinkel, De-Identification of Personal Information (NISTIR 8053), NIST, 2015. https://csrc.nist.gov/pubs/ir/8053/final ↩ ↩2 ↩3
-
개인정보 보호법(법률 제20897호, 시행 2025. 10. 2.), 법제처 국가법령정보센터. https://www.law.go.kr/lsInfoR.do?lsiSeq=270351&chrClsCd=010202&urlMode=lsInfoP&efYd=20251002 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11 ↩12 ↩13
-
Article 29 Data Protection Working Party, Opinion 05/2014 on Anonymisation Techniques (WP216), 2014. https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2014/wp216_en.pdf ↩ ↩2 ↩3 ↩4 ↩5
-
개인정보보호위원회, 가명정보 처리 가이드라인(2026. 3. 개정), 2026. https://www.pipc.go.kr/np/cop/bbs/selectBoardArticle.do?bbsId=BS217&mCode=G010030000&nttId=11931 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
Latanya Sweeney, Simple Demographics Often Identify People Uniquely, Carnegie Mellon University Data Privacy Working Paper 3, 2000. https://dataprivacylab.org/projects/identifiability/paper1.pdf ↩ ↩2 ↩3
-
Joseph Near, David Darais, Naomi Lefkovitz, Gary Howarth, Guidelines for Evaluating Differential Privacy Guarantees (NIST SP 800-226), NIST, 2025. https://csrc.nist.gov/pubs/sp/800/226/final ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Arvind Narayanan, Vitaly Shmatikov, How To Break Anonymity of the Netflix Prize Dataset (IEEE S&P 2008 발표 논문의 arXiv판), arXiv:cs/0610105. https://arxiv.org/abs/cs/0610105 ↩ ↩2
-
Cynthia Dwork, Aaron Roth, The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf ↩
-
Aloni Cohen, Kobbi Nissim, Towards Formalizing the GDPR's Notion of Singling Out, PNAS 117(15), 2020. https://arxiv.org/abs/1904.06009 ↩ ↩2
-
Damien Desfontaines, Balázs Pejó, SoK: Differential Privacies, Proceedings on Privacy Enhancing Technologies 2020(2). https://arxiv.org/abs/1906.01337 ↩